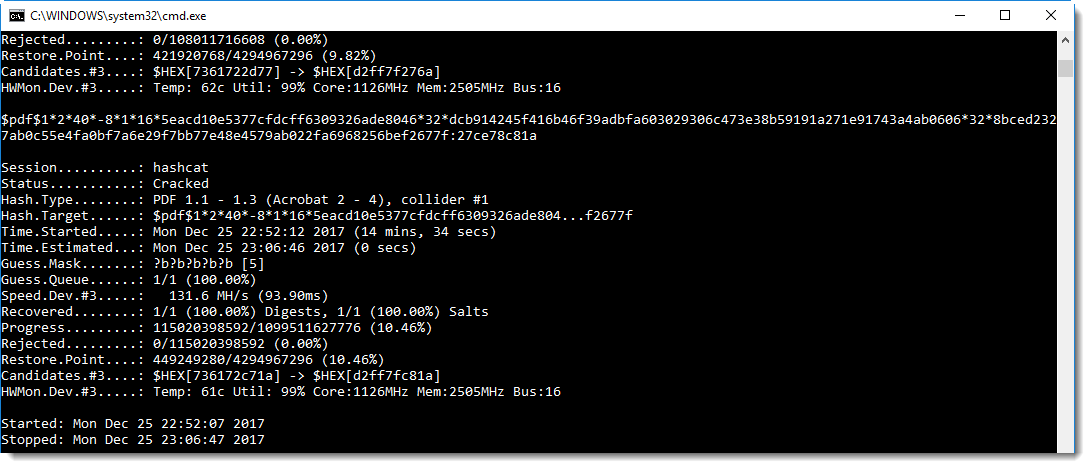
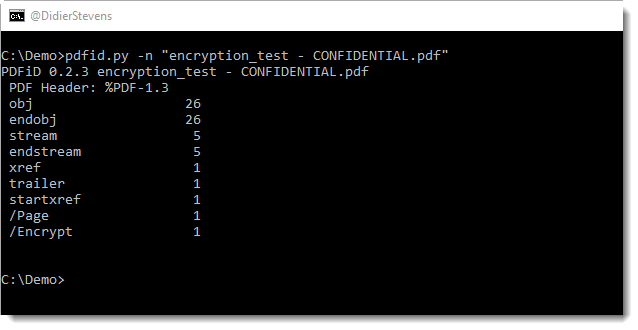
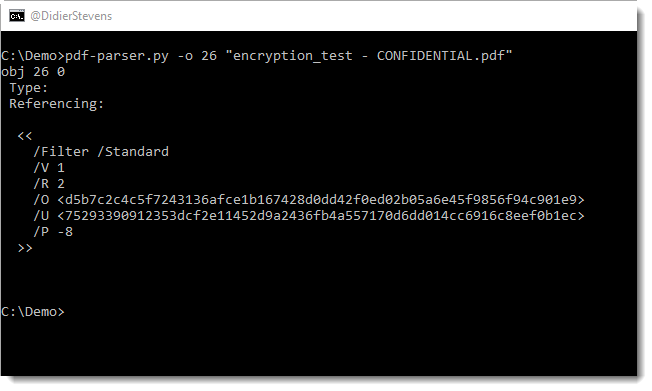
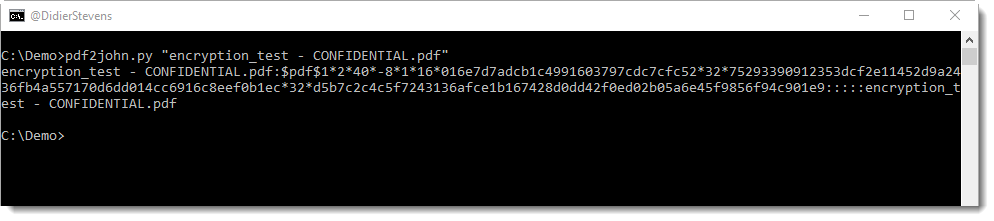
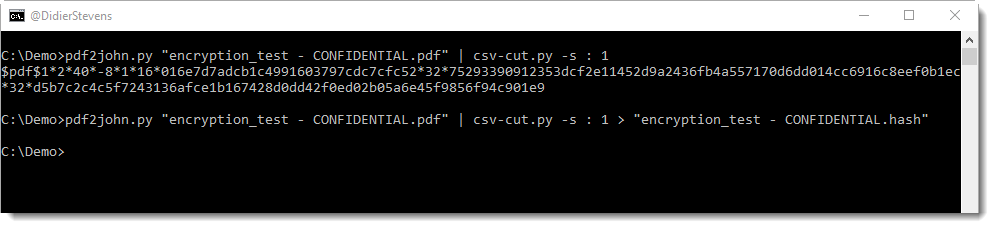
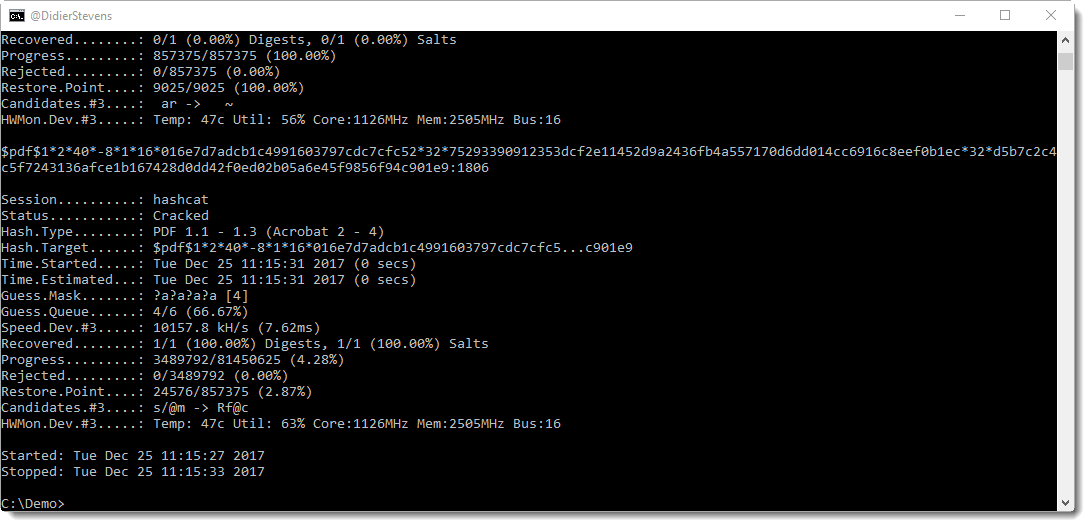
I performed a brute-force attack on the password of an encrypted PDF and a brute-force attack on the key of (another) encrypted PDF, both PDFs are part of a challenge published by John August.
The encryption key is derived from the password. it’s not just based on the password only, but also on metadata. This implies that different PDFs encrypted with the same user password, will have different encryption keys.
When you recover the user password of an encrypted PDF, you can just use it with PDF readers like Adobe Reader: they will ask you for the password, you provide it and the PDF will be decrypted and rendered.
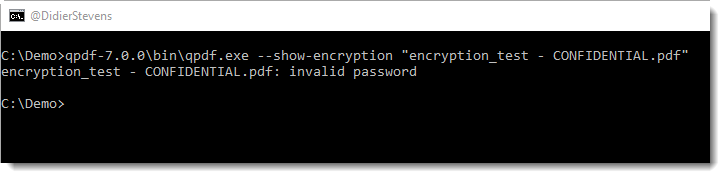
But when you recover the key of an encrypted PDF, you can not use it with PDF reader: there is no feature that will allow you to input a key in stead of a password. The only method I knew to decrypt a PDF document with its encryption key, was to use Elcomsoft’s PDF cracking tool:
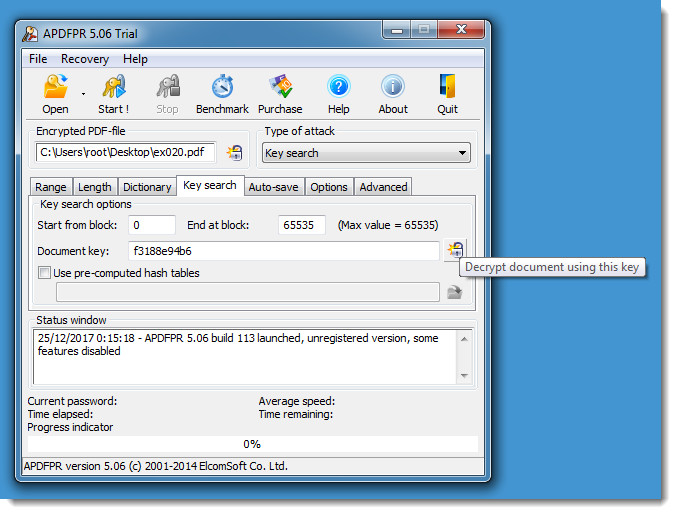
Now I worked out a second method: I modified the source code of QPDF so that it will accept encryption keys too. It’s a quick and dirty hack, I did not add a new option to QPDF but I “hijacked” the –password option. If the value to the option –password starts with string “key:”, then QPDF will not derive the key from the provided password, but it will use the key provided as hexadecimal characters. Here is how I use it to decrypt the “tough” PDF:

I also made a small modification to the –show-encryption option, to display the encryption key:
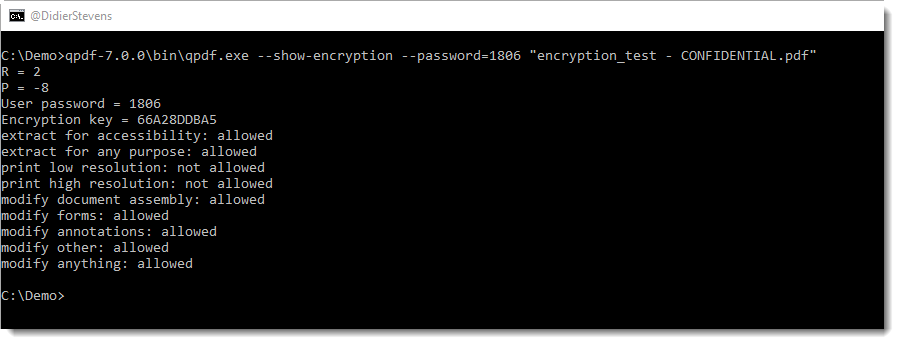
Update: I had an email exchange with Jay Berkenbilt, the author of QPDF, and he will look into this patch and possibly add a new key option to QPDF.
If you are interested in my modified version of QPDF, you can find the modified source code files and Windows binaries here:
qpdf-patched.zip (https)
MD5: 57E1A5A232E12B45D0A927181A1E8C3B
SHA256: 6F17E095B38AE72F229A6662216DDCE86057D2BA1C567B07FEF78B8A93413495
Update: this is the complete blog post series:
-
- Cracking Encrypted PDFs – Part 1: cracking the password of a PDF and decrypting it
- Cracking Encrypted PDFs – Part 2: cracking the encryption key of a PDF
- Cracking Encrypted PDFs – Part 3: decrypting a PDF with its encryption key (what you are reading now)
- Cracking Encrypted PDFs – Conclusion: don’t use 40-bit keys