I’m teaching a 2-day class “Analysing Malicious Documents” at 44CON London.
Here is my promo video:
If you get an error running one of my tools, first make sure you have the latest version. Many tools have a dedicated page, but even more tools have no dedicated page but a few blogposts. Check “My Software” list for the latest versions.
Most of my tools are written in Python or C.
Almost all of my Python tools are written for Python 2 and not Python 3. My PDF tools pdfid and pdf-parser are an exception: they are designed to run with Python 2 and Python 3.
If you get a syntax error running one of my Python tools, then it’s most likely that you are using Python 3 with a tool written for Python 2. Remove Python 3 and install Python 2.
Most of my tools use only build-in Python modules, you don’t need to install extra modules. Some tools that require extra modules will print a warning when you run them without the extra module installed. My tools that support Yara rules require the Yara module, but you will only get a warning for a missing Yara module if you use Yara rules. You can use the tool without the Yara module as long as you don’t use Yara rules.
I develop my tools on Python 2. My few Python tools written for Python 2 and Python 3 are also developed on Python 2, but only tested on Python 3.
My tools written in C are developed with Borland C++ or Visual Studio 2013.
The tools compiled with Borland C++ don’t require a C runtime to be installed.
The tools compiled with Visual Studio 2013 come in several versions:
There are a couple of scripts and programs available on the Internet to extract the configuration of the Dyre banking malware from a memory dump. What I’m showing here is a method using a generic regular expression tool I developed (re-search).
Here is the Dyre configuration extracted from the strings found inside the memory dump:

I want to produce a list of the domains found as first item in an <litem> element. re-search is a bit like grep -o, it doesn’t select lines but it selects matches of the provided regular expression. Here I’m looking for tag <litem>:

By default, re-search will process text files line-by-line, like grep. But since the process memory dump is not a text file but a binary file, it’s best not to try to process it line-by-line, but process it in one go. This is done with option -f (fullread).
Next I’m extending my regular expression to include the newline characters following <litem>:

And now I extend it with the domain (remark that the Dyre configuration supports asterisks (*) in the domain names):

If you include a group () in your regular expression, re-search will only output the matched group, and not the complete regex match. So by surrounding the regex for the domain with parentheses, I extract the domains:

This gives me 1632 domains, but many domains appear more than once in the list. I use option -u (unique) to produce a list of unique domain names (683 domains):

Producing a sorted list of domain names is not simple when they have subdomains:
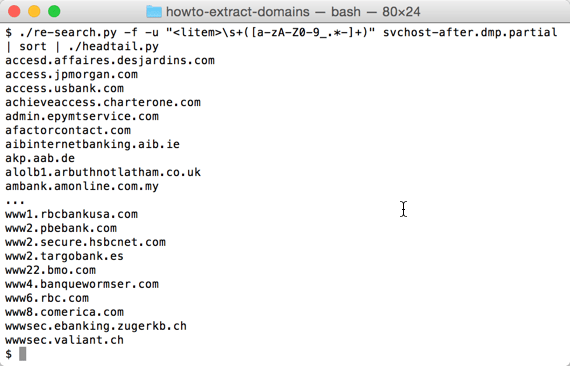
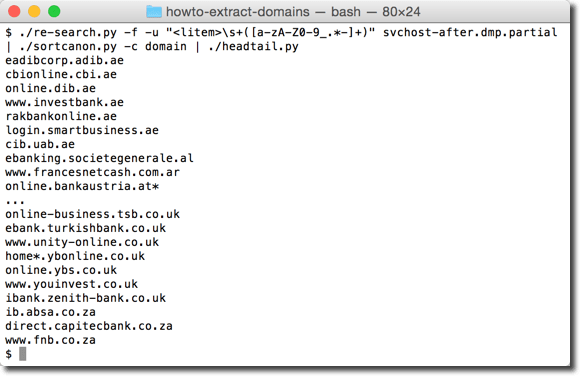
That’s why I have a tool to sort domains by tld first, then domain, then subdomain, …
re-search_V0_0_1.zip (https)
MD5: 5700D814CE5DD5B47F9C09CD819256BD
SHA256: 8CCF0117444A2F28BAEA6281200805A07445E9A061D301CC385965F3D0E8B1AF
A new tool, a new video:
base64dump_V0_0_1.zip (https)
MD5: 350C12F677E08030E0DD95339AC3604D
SHA256: 1F8156B43C8B52B7E5620B7A8CD19CFB48F42972E8625994603DDA47E07C9B35
