Compiled Windows (Cygwin) and Linux (Ubuntu) executables can be found here.
This change introduces a new format: $pdfo$.
There is no tool for the moment to create this format. Just use pdf2john.pl to create a $pdf$ hash, and then change it into a $pdfo$ hash. To crack the owner password, one needs to recover the user password first.
Cracking PDF owner passwords is just an academic exercise (writing this code was also just an exercise), as tools like QPDF can decrypt PDFs encrypted with a PDF owner password only without requiring the cleartext PDF owner password as argument.
I recently created 2 blog posts with corresponding videos for the reversing of encodings.
The first one is on the ISC diary: “Decoding Obfuscated BASE64 Statistically“. The payload is encoded with a variation of BASE64, and I show how to analyze the encoded payload to figure out how to decode it.
And this is the video for this diary entry:
And on this blog, I have another example, more complex, where the encoding is a variation of hexadecimal encoding, with some obfuscation: “Another Exercise In Encoding Reversing“.
In this blog post, I will show how to decode a payload encoded in a variation of hexadecimal encoding, by performing statistical analysis and guessing some of the “plaintext”.
I do have the decoder too now (a .NET assembly), but here I’m going to show how you can try to decode a payload like this without having the decoder.
Seeing all these letters, I thought: this is lowercase Netbios Name encoding. That is an encoding where each byte is represented by 2 hexadecimal characters, but the characters are all letters, in stead of digits and letters. Since my tool base64dump.py can handle netbios name encoding, I let it try all encodings:
That failed: no netbios encoding was found. Only base64 and 2 variants of base85, but that doesn’t decode to anything I recognize. Plus, for the last 2 decodings, only 17 unique characters were found. That makes it very unlikely that it is indeed base64 or base85.
Next I use my tools byte-stats.py to produce statistics for the bytes found inside the payload:
There are 17 unique bytes used to encode this payload. The ranges are:
abcdef
i
opqrstuvw
y
This is likely some form of variant of hexadecimal encoding (16 characters) with an extra character (17 in total).
You will find this default processing code in the template:
I am replacing this default code with the following code (I will post a link to the complete program at the end of this blog post):
The content of the file is in variable data. These are bytes.
Since I’m actually dealing with letters only, I’m converting these bytes to characters and store this into variable encodedpayload.
The next piece of code, starting with “data = []” and ending with “data = bytes(data)”, will read two characters from the encodedpayload, and try to convert them from an hexadecimal byte to a byte. If that fails (ValueError), that pair of characters is just ignored.
And then, the last statement, I do an hexadecimal/ascii dump of the data that I was able to convert. This gives me the following:
That doesn’t actually make me any wiser.
Looking at the statistics produced by byte-stats.py, I see that there are 2 letters that appear most frequently, around 9% of the time: d and q.
I do know that the payload is a Windows executable (PE file). PE files that are not packed, contain a lot of NULL bytes. Character 0 is by far the most frequent when we do a frequency analysis of the hexadecimal representation of a “classic” PE file. It often has a frequency of 20% or higher.
That is not the case here for letters d and q. So I don’t know which letter represents digit 0.
Let’s make a small modification to the program, and represent each pair of characters that couldn’t be decoded as hexadecimal, by a NULL byte (data.append(0):
This code produces the following output:
And that is still not helpful.
Since I know this is a PE file, I know the file has to start with the letters MZ. That’s 4D5A in hexadecimal.
The encoded payload starts with ydua. So let’s assume that this represents MZ (4D5A in hexadecimal), thus y is 4, d is d, u is 5 and a is a.
I will now add a small dictionary (dSubstitute) with this translation, and add code to do a search and replace for each of these letters (that’s the for loop):
This code produces the following output:
Notice that apart from MZ, letters DO also appear. DO is 444F in hexadecimal, and is part of the well-known string found at the beginning of (most) PE files: !This program cannot be run in DOS mode
I will know use this string to try to match more letters with hexadecimal digits (I’m assuming the PE file contains this string).
I add the following lines to print out string “!This program cannot be run in DOS mode” in hexadecimal:
This results in the following output:
Notice that the letter T is represented as 54 in hexadecimal. Hexadecimal digits 5 and 4 are part of the digits we already decoded. 5 is u and and 4 is y.
I add code to find the position of the first occurrence of string uy inside the encoded payload:
And this is the output:
Position 86. That’s at the beginning of the payload, so it’s possible that I have found the location of the encoded string “!This program cannot be run in DOS mode”.
I will now add code that does the following: for each letter of the encoded string, I will lookup the corresponding hexadecimal digit in the hexadecimal representation of the unencoded string, and add this decoding pair to the dictionary. If the letter that I add to the dictionary is already present in the dictionary, I compare the stored hexadecimal digit for that letter with the one I looked up, and if they are different, I generate an exception. Because if that happens, I don’t have a one-to-one relationship, and my hypothesis that this is a variant of hexadecimal, is wrong. This is the extra code:
After completing the dictionary, I do a return. I don’t want to do the decoding yet, I just want to make sure that no exception is generated by finding 2 different hexadecimal digits. This is the output:
No exception was thrown: we have a one-to-one relationship.
Next I add 2 lines to see how many and what letters I have inside the dictionary:
This is the output:
That is 14 letters (we have 17 in total). That’s a great result.
I remove the return statement now, to let the decoding take place:
Giving this result:
That is a great result. Not only do I see strings MZ and “!This program cannot be run in DOS mode”, but also PE, .text, .data, .rdata, …
I am now adding code to see which letters I’m still missing:
Giving me this output:
The letters I still need to match to hexadecimal digits are: b, c and q.
I want to know where these letters are found inside the partially decoded payload, and for that I add the following code:
Giving me this result:
The letter q appears very soon: as the 6th character.
Let’s compare this with the start of another, well-known PE file: notepad.exe:
So notepad.exe starts with 4d5a90000300000004
And the partially decoded payload starts with: 4d5a9q03qq04
Let’s put that right under each other:
4d5a90000300000004
4d5a9q03qq04
If I replace q with 000, I match the beginning of notepad.exe.
4d5a90000300000004
4d5a90000300000004
I add this to the dictionary:
And run the program:
That starts to look like a completely decoded PE file.
But I still have letters b and c.
I’m adding some code to see which hexadecimal characters are left unpaired with a letter:
Output:
Hexadecimal digits b and c have not been paired with a letter.
Now, since a translates to a, d to d, e to e and f to f, I’m going to guess that b translates to b and c to c.
I’m adding code to write the decoded payload to disk:
And after running one more time my script, I’m using my tool pe-check.py to validate that I have indeed a properly decoded PE file:
This looks good.
From the process memory dump I have for this malware, I know that I’m dealing with a Cobalt Strike beacon. Let’s check with my 1768.py tool:
This is indeed a Cobalt Strike beacon.
The encoding that I reversed here, is used by GootLoader to encode beacons. It’s an hexadecimal representation, where the decimal digits have been replaced by letters other that abcdef. With an extra twist: while letter v represents digit 0, letter q represent digits 000.
The complete analysis & decoding script can be found here.
sortcanon.py is a tool to sort text files according to some canonicalization function. For example, sorting domains or ipv4 addresses.
This is actually an old tool, that I still had to publish. I just updated it to Python 3.
This is the man page:
Usage: sortcanon.py [options] [files]
Sort with canonicalization function
Arguments:
@file: process each file listed in the text file specified
wildcards are supported
Valid Canonicalization function names:
domain: lambda x: '.'.join(x.split('.')[::-1])
ipv4: lambda x: [int(n) for n in x.split('.')]
length: lambda x: len(x)
Source code put in the public domain by Didier Stevens, no Copyright
Use at your own risk
https://DidierStevens.com
Options:
--version show program's version number and exit
-h, --help show this help message and exit
-m, --man Print manual
-c CANONICALIZE, --canonicalize=CANONICALIZE
Canonicalization function
-r, --reverse Reverse sort
-u, --unique Make unique list
-o OUTPUT, --output=OUTPUT
Output file
Manual:
sortcanon is a tool to sort the content of text files according to some
canonicalization function.
The tool takes input from stdin or one or more text files provided as argument.
All lines from the different input files are put together and sorted.
If no option is used to select a particular type of sorting, then normal
alphabetical sorting is applied.
Use option -o to write the output to the given file, in stead of stdout.
Use option -r to reverse the sort order.
Use option -u to produce a list of unique lines: remove all doubles before
sorting.
Option -c can be used to select a particular type of sorting.
For the moment, 2 options are provided:
domain: interpret the content of the text files as domain names, and sort them
first by TLD, then domain, then subdomain, and so on ...
length: sort the lines by line length. The longest lines will be printed out
last.
ipv4: sort IPv4 addresses.
You can also provide your own Python lambda function to canonicalize each line
for sorting.
Remark that this involves the use of the Python eval function: do only use this
with trusted input.
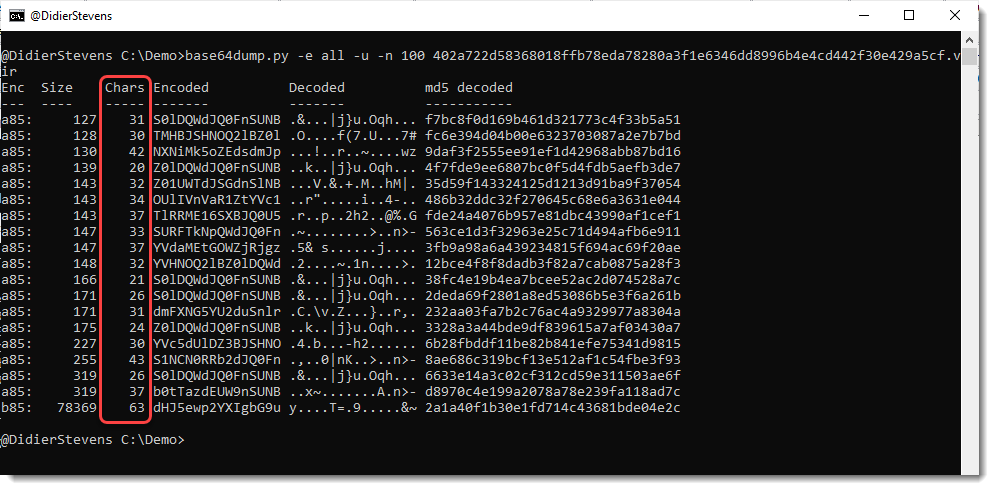
This new version of base64dump.py adds some extra info for the encoded strings.
In -e all mode, a new column Chars tells you how many unique characters are used for that encoded string:
For example, the last line is recognized as a syntactically valid variant of BASE85 (b85), but it uses only 63 unique characters (85 unique characters is the maximum). So this is probably not b85, or else the encoded data has low entropy.
And there is also new info when you select a string for info:
While developing my oledump plugin plugin_olestreams.py, I noticed that the item moniker’s name field (lpszItem) values I observed while analyzing Follina RTF maldocs, had a value looking like _1715622067:
The number after the underscore (_), is derived from the timestamp when the item moniker was created. That timestamp is expressed as an epoch value in local time, to which a constant number is added: 61505155.
I figured this out by doing some tests. 61505155 is an approximation: I might be wrong by a couple of seconds.
Item name _1715622067 is the value you find in Follina maldocs created from this particular RTF template made by chvancooten. 1715622067 minus 61505155 is 1654116912. Converting epoch value 1654116912 to date & time value gives: Wednesday, June 1, 2022 8:55:12 PM. That’s when that RTF document was created.
RTF documents made from this template, can be detected by looking for string 0c0000005f3137313536323230363700 inside the document (you have to look for this hexadecimal string, not case sensitive, because OLE files embedded in RTF are represented in hexadecimal).
Notice that the newest template in that github repository is taken from a cve-2017-0199 RTF template document, and that it no longer contains a item moniker.
But it does contain another timestamp:
This hexadecimal string can also be used for detection purposes: 906660a637b5d201
I used the following YARA rules for a retrohunt (34 matches):
Notice that I do not include a test for RTF documents in my rules: these rules also detect Python program follina.py.
And if you are a bit familiar with the RTF syntax, you know that it’s trivial to modify such RTF documents to avoid detection by the above YARA rules.
Later I will spend some time to find the actual code that implements the generation of the item value _XXXXXXXXXX. Maybe you can find it, or you already know where it is located.
dns-query-async.py is a tool to perform DNS queries in parallel.
This is the man page:
Usage: dns-query-async.py [options] command file
Program to perform asynchronous DNS queries
accepted commands: gethost,getaddr
Source code put in the public domain by Didier Stevens, no Copyright
Use at your own risk
https://DidierStevens.com
Options:
--version show program's version number and exit
-h, --help show this help message and exit
-m, --man Print manual
-o OUTPUT, --output=OUTPUT
Output to file (# supported)
-s NAMESERVERS, --nameservers=NAMESERVERS
List of nameservers (,-separated)
-n NUMBER, --number=NUMBER
Number of simultaneous requests (default 10000)
-t TRANSFORM, --transform=TRANSFORM
Transform input (%%)
Manual:
This tool performs asynchronous DNS queries. By default, it will perform 10000
queries simultaneously.
The first argument is a command. There are 2 commands for the moment: gethost
and getaddr
The second argument is a filename: a text file containing the items to resolve.
Use command getaddr to lookup the IP address of the hostnames provided in the
input file.
Example:
dns-query-async.py getaddr names.txt
Result:
didierstevens.com,1,96.126.103.196
didierstevenslabs.com,1,96.126.103.196
Duration: 0.20s
Use command gethost to lookup the hostnames of the IP addresses provided in the
input file.
Example:
dns-query-async.py gethost ips.txt
Use option -s to provide the name servers to use (comma separated list).
Use option -n to change the number of asyncio workers (10000 default).
Use option -t to transform the input list and perform lookups.
For example, take list of subdomains/hostnames https://github.com/m0nad/DNS-
Discovery/blob/master/wordlist.wl
Issue the following command:
dns-query-async.py -t %%.example.com getaddr wordlist.wl
Result:
0.example.com,0,Domain name not found
009b.example.com,0,Domain name not found
01.example.com,0,Domain name not found
02.example.com,0,Domain name not found
03.example.com,0,Domain name not found
1.example.com,0,Domain name not found
10.example.com,0,Domain name not found
101a.example.com,0,Domain name not found
The %% in %%.example.com is replaced by each hostname/subdomain in wordlist.wl
and then resolved.
Use option -o to write the output to a file.