Steganography is the art of hiding messages so that uninitiated wouldn’t suspect the presence of a message. A rainbow table is a huge binary file used for password cracking. This is the first in a series of posts on research I’ve done on how to hide data in rainbow tables, and how to detect its presence.
There are several steganography algorithms to hide data in pictures. They often involve changing the least-significant-bits of the numbers representing the color or another visual property of a pixel. This minute difference cannot be perceived by the naked eye, but it this there. The size of the data you can hide in a picture is limited by the size of the picture and by the numbers of bits involved in the steganography algorithm. It’s impossible to hide large files, like audio or video files, in a picture, unless you split the files and use a lot of pictures. To hide a large amount of data in a single file, you need a large file.
Rainbow tables are huge, usually 1 à 2 GB. I’ve generated a set of LM-hash rainbow tables that is 23 GB. So there should be enough space to hide a large amount of data. The software I’ve used in my research is from Project RainbowCrack. All tables used in my research were generated with this software.
The first method to hide data with a rainbow table is trivial, just rename the file you want to hide to the name of a rainbow table, like this one: lm_alpha-numeric-symbol14-space#1-7_0_5400x67108864_0.rt
But this method will not withstand a superficial inspection of the file. A forensic analyst will see through your subterfuge, by looking at the content of this file she will recognize the format of the media file you’ve renamed and realize that it’s not a rainbow table.
So how can you hide data in a real rainbow table? Let’s look at the structure of a rainbow table.
A rainbow table is just a sequence of records. Each record has 2 fields of 8 bytes each, this makes a record 16 bytes wide. Therefore the size of a rainbow table is a multiple of 16. A record represents a chain. The first field is the password that started the chain. Actually, the first field is an index into the keyspace of all possible passwords for the given rainbow table set. It is a random number between 0 and the size of the keyspace – 1. The second field is the hash of the last password in the chain (actually, this is also an index and not the real hash). The rainbow table is sorted on the second field: the record with the lowest hash is first in the table and the one with the highest hash is last.
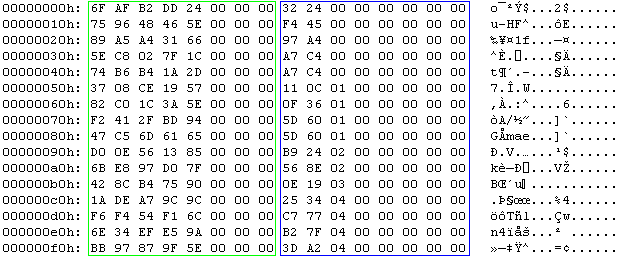
This is the hex dump a rainbow table (the first 16 chains). The green box highlights the random data, notice that the 3 most-significant-bytes are 0. The blue box highlights the hash, notice that this column is sorted.
My second method will modify a real rainbow table to hide a file.
Because the first field is just a random number, we can replace it with our own data from the file we want to hide. We cannot use all the bytes in this field, because the size of the keyspace is usually smaller than 8 bytes wide. The most-significant-bits of the password field are set to zero. Setting them to one would give our secret away. We must limit our usage of the password field to the least-significant-bytes. Changing these bytes will not change the structure of the rainbow table, so it will still appear as a valid rainbow table. The only consequence of our change is that the chain cannot be used anymore to crack a password. But if we leave a certain percentage of chains in the rainbow table unchanged, the rainbow table can still be used to crack some passwords.
To illustrate the technique, we insert 32 bytes (the sequence from 0x00 through 0x1F) in this rainbow table:

We will replace the random bytes in the red box. The keyspace of this rainbow table is less than 5 bytes (0xFFFFFFFFFF), that’s why I decide to change only the 4 least significant bytes of the start of a chain. This is the result:

It is clear that this modification is very obvious when you look at it, because the start entries are not random anymore. But if you use data that looks random (using compression or encryption), it will not stand out from the other random bytes. You can even use this modified rainbow table to crack passwords. The first 8 chains will not crack passwords anymore, because the start of the chain has been changed. But this does not cause an error and all the other chains are still usable. The only way to detect the hidden bytes (other than statistical analysis), is to recalculate the chain and compare the calculated hash with the stored hash. If they differ, the start has been tampered with. You can do this with the rtdump command, like this:
rtdump lm_alpha-numeric-symbol14-space#1-7_0_5400x67108864_0.rt 0
If the chain has been modified, the message will be:

The problem with this test is that it is very time consuming, checking a complete rainbow table takes about as much time as calculating the rainbow table, because you’re in fact recalculating all the chains. FYI, each 1 GB table from my set took about 1 week to generate.
You can find PoC code to store and retrieve data in rainbow tables here in this ZIP file.
Use rthide to hide data in a rainbow table, it takes 5 arguments:
- the rainbow table (remains unchanged)
- the file to hide (remains unchanged)
- the new rainbow table
- the number of the first chain where we will start replacing the random start bytes
- the number of bytes per chain we replace
To hide a file data.zip at the start of a rainbow table called lm_alpha-numeric-symbol14-space#1-7_0_5400x67108864_0.rt, using only 4 bytes per chain, use this command:
rthide lm_alpha-numeric-symbol14-space#1-7_0_5400x67108864_0.rt data.zip lm_alpha-numeric-symbol14-space#1-7_0_5400x67108864_0.rt.stego 0 4
This will create a new rainbow table called lm_alpha-numeric-symbol14-space#1-7_0_5400x67108864_0.rt.stego
Use rtreveal to extract data from a rainbow table, it takes 5 arguments:
- the rainbow table
- the file to create
- the number of the first chain where we will start replacing the random start bytes
- the number of bytes per chain we replace
- the size of the hidden file
To extract the data, issue this command (you have to know the length of the hidden file, my PoC program doesn’t store this).
rtreveal lm_alpha-numeric-symbol14-space#1-7_0_5400x67108864_0.rt.stego data.zip 0 4 1620
1620 is the length of file data.zip
You can store a huge amount of data in a couple of minutes with this technique: for a rainbow table 1GB large, you can hide a 256 MB file in it using 4 bytes per chain. There is a way to detect the hidden data, but at a significant cost.
Stay tuned for posts about other techniques to hide data in rainbow tables.


