Sometimes I want to see the content of (malicious) .docx files without using MS Office. I will use my zipdump.py tool to extract the XML file with the content, and then use sed or translate.py to strip out XML tags.
But that doesn’t always yield the best results. Here is a small tool, xmldump, that will parse an XML file and output the text.
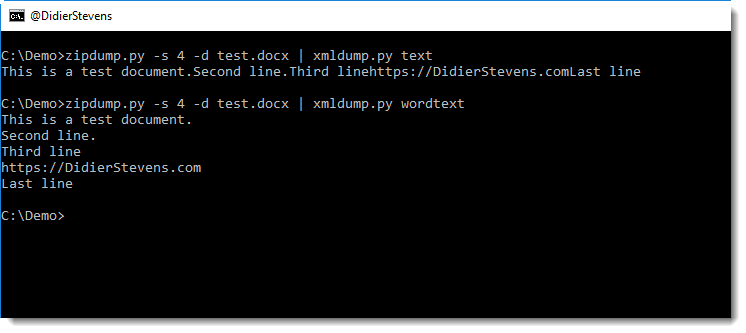
It supports 2 commands for the moment: text and wordtext.
Command text extracts the text between any XML tags.
Command wordtext extracts the text between Word paragraph XML tags (<w:p>) and prints each paragraph’s text on a separate line.
xmldump_V0_0_1.zip (https)
MD5: 23D5643E45B97D6AE641DF6CAFA79370
SHA256: A999F2297EE44FAABCA5A025DAEC7E84CB30D34C68F181357BA439EBFE38A660

will it be able to extract the hyperlink ?
Comment by Anonymous — Monday 18 December 2017 @ 22:40
To extract hyperlinks (or email addresses, IPv4 addresses, …) use my tool re-search.py with option -n url.
Comment by Didier Stevens — Monday 18 December 2017 @ 22:43
[…] New Tool: xmldump.py […]
Pingback by Week 51 – 2017 – This Week In 4n6 — Sunday 24 December 2017 @ 3:06
[…] New Tool: xmldump.py […]
Pingback by Overview of Content Published In December | Didier Stevens — Tuesday 2 January 2018 @ 0:01