I must admit that I was (patiently) waiting for the type of malicious document I’m about to describe now. First I’m going to analyze this document with my tools, and after that I’m going to show you some of the mitigations put in place by Adobe and Microsoft.
Malicious document 123-148752488-reg-invoice.pdf is a PDF with an embedded file and JavaScript. Here is pdfid’s report:

As we can notice from this report, the PDF document contains /JavaScript and an /OpenAction to launch this JavaScript upon opening of the PDF file, and also an /EmbeddedFile.
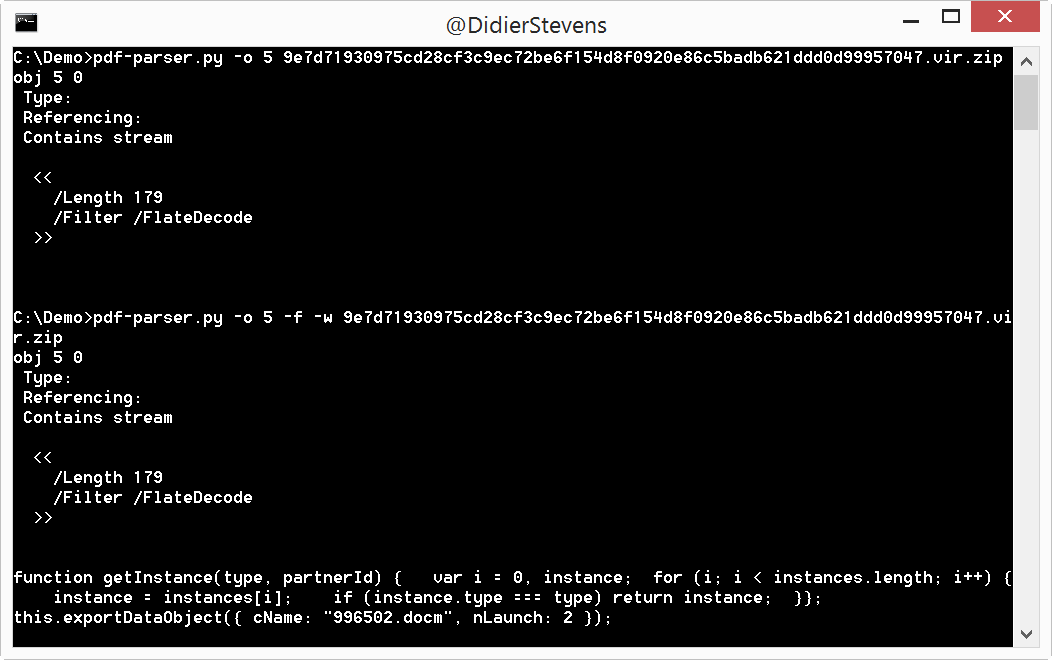
pdf-parser.py searching for JavaScript (option -s javascript) reveals that the JavaScript is in object 5:

Object 5 contains JavaScript (option -o 5 to select object 5, and option -f to decompress the stream with JavaScript):

This script (this.exportDataObject) will save the embedded file (996502.docm) to a temporary file and launch the associated application (if MS Office is installed, Word will be launched). A .docm file is a Word document with macros.
So let’s search for this embedded file:

The embedded file is stored in object 3, as a compressed stream (/FlateDecode).
So let’s decompress and extract the file with pdf-parser: option -f to filter (decompress) and option -d to dump the content. Since I expect the embedded file to be a Word document with macros, I’m going to analyze it with oledump. So in stead of writing the embedded file to disk, I’m going to extract it to stdout (-d -) and pipe it into oledump:

oledump‘s report confirms that it is a Word document with macros. I’m not going to spend much time on the analysis of the VBA code, because the intent of the code becomes clear when we extract all the strings found in the VBA code. First we select and extract all VBA code (options -s a -v) and then we pipe this into re-search to produce a list of unique strings (enclosed in double quotes) with these options: -n str -u

One of the extracted strings contains 3 URLs separated by character V. The macros will download an XOR encoded EXE file from these sites, decode it and execute it.
Mitigations
The first mitigation is in Adobe Reader: the embedded .docm file will not be extracted and launched without user interaction. First the user is presented a dialog box:

Only when clicking OK (the default option), will the .docm file be extracted and launched. Remark that the maldoc authors use some weak social engineering to entice the user to click OK: see in 996502.
When opened in Word, macros will be disabled:

This next mitigation is put into place by Microsoft Word: macros are detected, and by default, they are not executed. Here we see a better attempt at social engineering the user into executing the macros.
You might have expected that this document would be opened in Protected View first. After all, the PDF document was e-mailed to the victims, and Outlook will mark the PDF with a mark-of-web when it is saved to disk:

But Adobe Reader will not propagate that mark-of-web of the PDF document to the extracted Word document (at least the version I tested, version XI). Without mark-of-web, Word will open the document without Protected View.
Another simple mitigation for this type of malicious document that you can put into place but that is not enabled by default, is to disable JavaScript in Adobe Reader.
Remark that these documents do not contain exploits: they just use scripting.