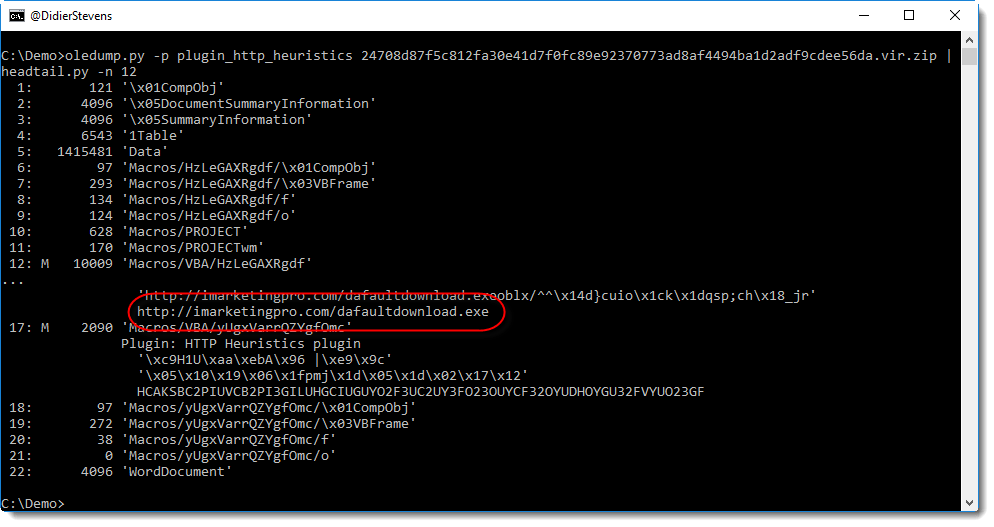
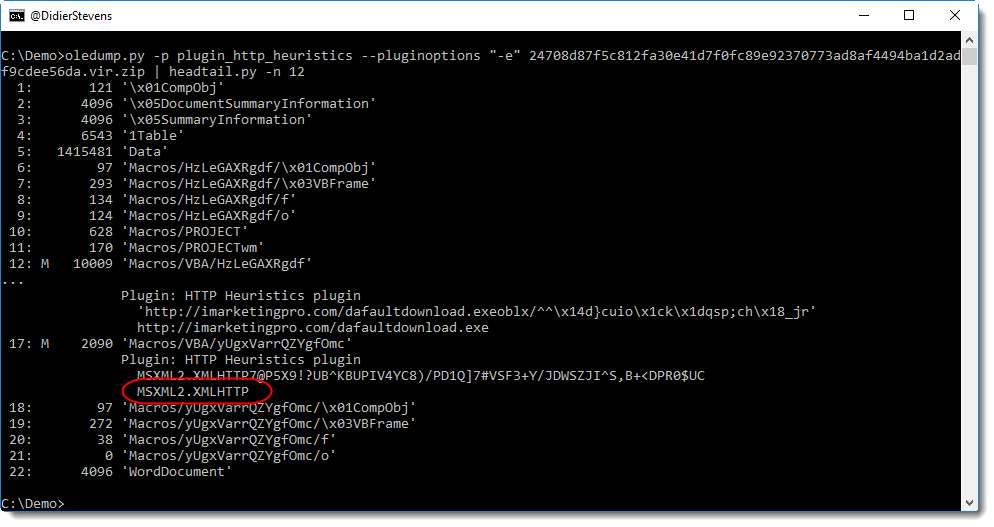
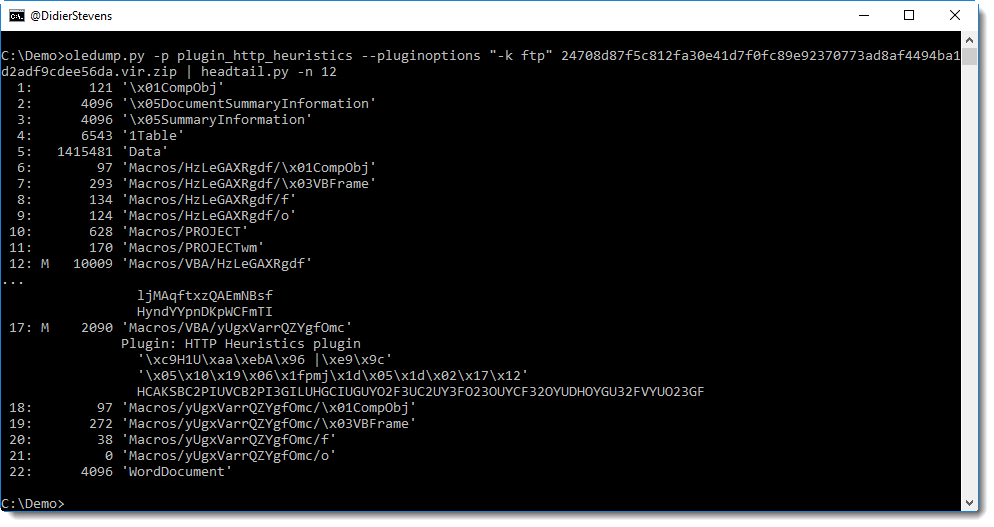
keihash.py is a program to parse pcap files and calculate the KEIHash of SSH connections.
The KEIHash is the MD5 hash of the Key Exchange Init (KEI) data (strings). For obvious reasons, I could not call this an SSH fingerprint. This is inspired by JA3 SSL fingerprinting.
It can be used to profile SSH clients and servers. For example, the hash for the latest version of PuTTY (SSH-2.0-PuTTY_Release_0.70) is 1c5eaa56f3e4569385ae5f82a54715ee.
This is the MD5 hash of:
240-curve25519-sha256@libssh.org,ecdh-sha2-nistp256,ecdh-sha2-nistp384,ecdh-sha2-nistp521,diffie-hellman-group-exchange-sha256,diffie-hellman-group-exchange-sha1,diffie-hellman-group14-sha1,rsa2048-sha256,rsa1024-sha1,diffie-hellman-group1-sha1;87-ssh-rsa,ssh-ed25519,ecdsa-sha2-nistp256,ecdsa-sha2-nistp384,ecdsa-sha2-nistp521,ssh-dss;189-aes256-ctr,aes256-cbc,rijndael-cbc@lysator.liu.se,aes192-ctr,aes192-cbc,aes128-ctr,aes128-cbc,chacha20-poly1305@openssh.com,blowfish-ctr,blowfish-cbc,3des-ctr,3des-cbc,arcfour256,arcfour128;189-aes256-ctr,aes256-cbc,rijndael-cbc@lysator.liu.se,aes192-ctr,aes192-cbc,aes128-ctr,aes128-cbc,chacha20-poly1305@openssh.com,blowfish-ctr,blowfish-cbc,3des-ctr,3des-cbc,arcfour256,arcfour128;155-hmac-sha2-256,hmac-sha1,hmac-sha1-96,hmac-md5,hmac-sha2-256-etm@openssh.com,hmac-sha1-etm@openssh.com,hmac-sha1-96-etm@openssh.com,hmac-md5-etm@openssh.com;155-hmac-sha2-256,hmac-sha1,hmac-sha1-96,hmac-md5,hmac-sha2-256-etm@openssh.com,hmac-sha1-etm@openssh.com,hmac-sha1-96-etm@openssh.com,hmac-md5-etm@openssh.com;9-none,zlib;9-none,zlib;0-;0-
These are all the strings found in the Key Exchange Init packet, prefixed by their length and concatenated with separator ;.
With this, I’ve been able to identify SSH clients with spoofed banners attempting to connect to my servers.

keihash_V0_0_1.zip (https)
MD5: 674D019A739679D9659D2D512A60BDD8
SHA256: DB7471F1253E3AEA6BFD0BA38C154AF3E1D1967F13980AC3F42BB61BBB750490