In this series of blog posts, I’ll explain how I decrypted the encrypted PDFs shared by John August (John wanted to know how easy it is to crack encrypted PDFs, and started a challenge).
Here is how I decrypted the “easy” PDF (encryption_test).
From John’s blog post, I know the password is random and short. So first, let’s check out how the PDF is encrypted.
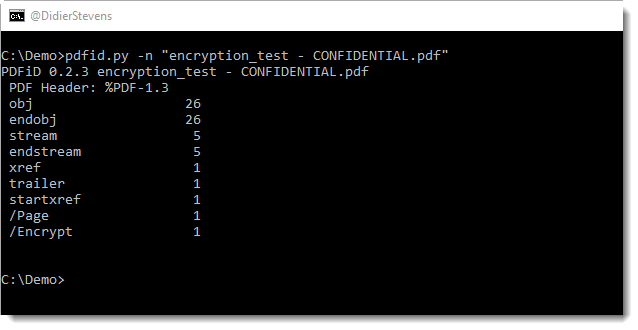
pdfid.py confirms the PDF is encrypted (name /Encrypt):
pdf-parser.py can tell us more:

The encryption info is in object 26:
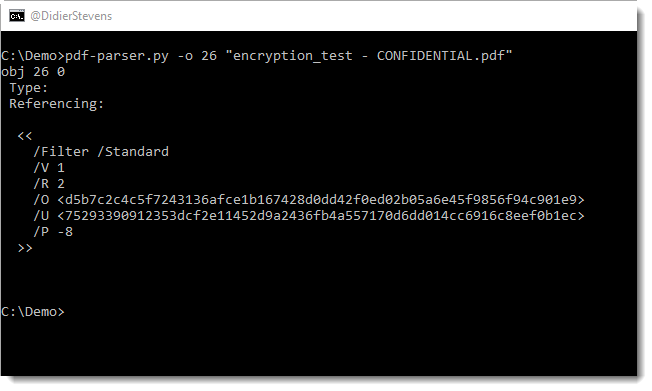
From this I can conclude that the standard encryption filter was used. This encryption method uses a 40-bit key (usually indicated by a dictionary entry: /Length 40, but this is missing here).
PDFs can be encrypted for confidentiality (requiring a so-called user password /U) or for DRM (using a so-called owner password /O). PDFs encrypted with a user password can only be opened by providing this password. PDFs encrypted with a owner password can be opened without providing a password, but some restrictions will apply (for example, printing could be disabled).
QPDF can be used to determine if the PDF is protected with a user password or an owner password:
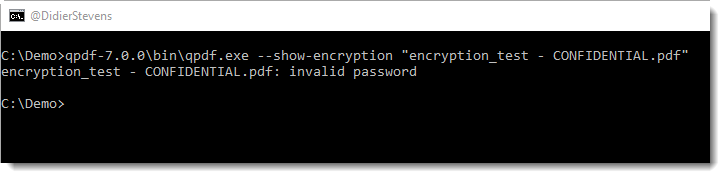
This output (invalid password) tells us the PDF document is encrypted with a user password.
I’ve written some blog posts about decrypting PDFs, but because we need to perform a brute-force attack here (it’s a short random password), this time I’m going to use hashcat to crack the password.
First we need to extract the hash to crack from the PDF. I’m using pdf2john.py to do this. Remark that John the Ripper (Jumbo version) is now using pdf2john.pl (a Perl program), because there were some issues with the Python program (pdf2john.py). For example, it would not properly generate a hash for 40-bit keys when the /Length name was not specified (like is the case here). However, I use a patched version of pdf2john.py that properly handles default 40-bit keys.
Here’s how we extract the hash:
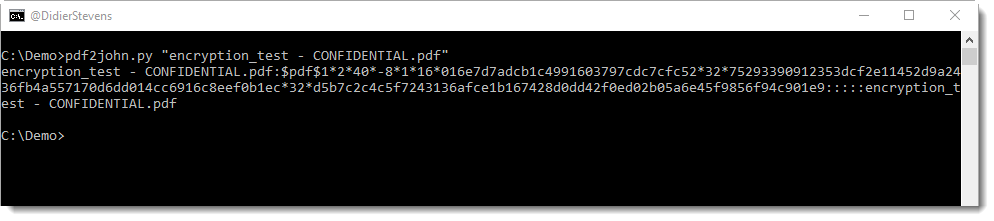
This format is suitable for John the Ripper, but not for hashcat. For hashcat, just the hash is needed (field 2), and no other fields.
Let’s extract field 2 (you can use awk instead of csv-cut.py):
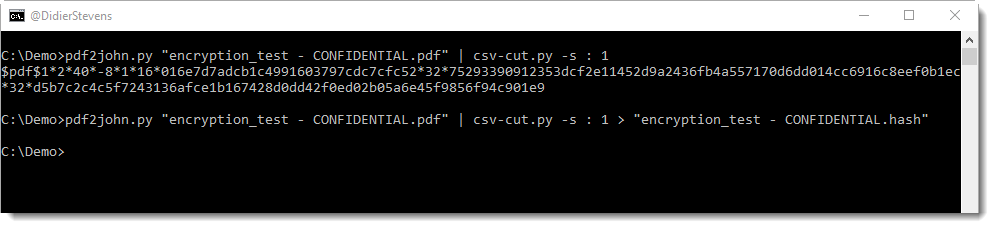
I’m storing the output in file “encryption_test – CONFIDENTIAL.hash”.
And now we can finally use hashcat. This is the command I’m using:
hashcat-4.0.0\hashcat64.exe --potfile-path=encryption_test.pot -m 10400 -a 3 -i "encryption_test - CONFIDENTIAL.hash" ?a?a?a?a?a?a
I’m using the following options:
- –potfile-path=encryption_test.pot : I prefer using a dedicated pot file, but this is optional
- -m 10400 : this hash mode is suitable to crack the password used for 40-bit PDF encryption
- -a 3 : I perform a brute force attack (since it’s a random password)
- ?a?a?a?a?a?a : I’m providing a mask for 6 alphanumeric characters (I want to brute-force passwords up to 6 alphanumeric characters, I’m assuming when John mentions a short password, it’s not longer than 6 characters)
- -i : this incremental option makes that the set of generated password is not only 6 characters long, but also 1, 2, 3, 4 and 5 characters long
And here is the result:
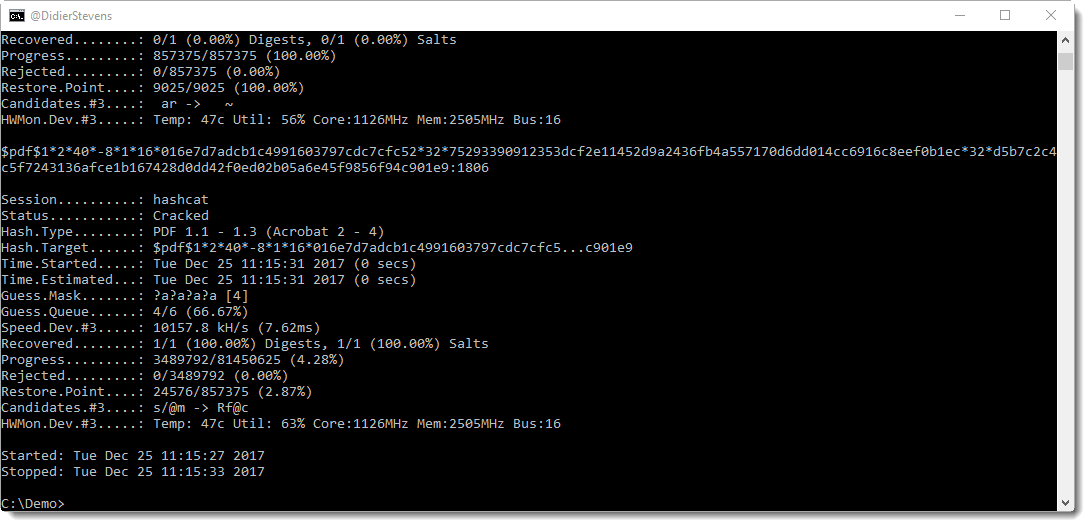
The recovered password is 1806. We can confirm this with QPDF:
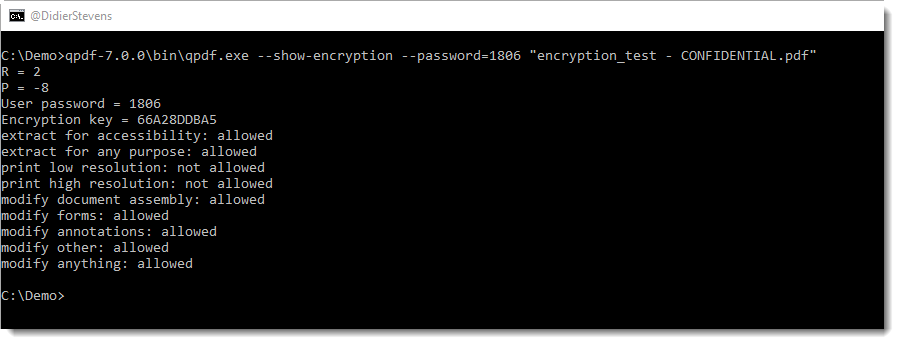
Conclusion: PDFs protected with a 4 character user password using 40-bit encryption can be cracked in a couple of seconds using free, open-source tools.
FYI, I used the following GPU: GeForce GTX 980M, 2048/8192 MB allocatable, 12MCU
Update: this is the complete blog post series:
-
-
- Cracking Encrypted PDFs – Part 1: cracking the password of a PDF and decrypting it (what you are reading now)
- Cracking Encrypted PDFs – Part 2: cracking the encryption key of a PDF
- Cracking Encrypted PDFs – Part 3: decrypting a PDF with its encryption key
-
- Cracking Encrypted PDFs – Conclusion: don’t use 40-bit keys
-

I assume that 1806 is the recovered password for the user hash. I may be mis-interpreting what you have posted, but bare with me.
Is there a reason that it didn’t solve for the owner hash? Did your qpdf not check for an owner pw because you didn’t specify it? pdf-parser.py did return a hash for an owner value.
If you knew there was no owner pw, why pass those hashes to John and hascat?
…and finally 🙂 How well does the test go if you cannot give it the number of characters to test for (which is normally the case in the wild).
Comment by Anonymous — Tuesday 26 December 2017 @ 19:12
There is a /O entry (“the owner hash”), but there is no owner password. The algorithms that calculates the value for the /U and /O dictionary entries always produce a value, even if the user password or the owner password is empty. If the owner password is empty, the algorithm for the /O entry (algorithm 3) will use the user password.
There is no need to crack the owner password if one has been specified: qpdf can decrypt a PDF protected with a owner password without having to provide that password to qpdf. You don’t need that password to decrypt the PDF, just like you don’t need that password to open that PDF with a PDF reader.
For your last question: you’ll have to wait for part 2 tomorrow (00:00 UTC) 🙂 I will decrypt a PDF protected with a 32 character long random password.
Comment by Didier Stevens — Tuesday 26 December 2017 @ 20:12
[…] cracking the “easy” PDF of John’s challenge, I’m cracking the “tough” PDF […]
Pingback by Cracking Encrypted PDFs – Part 2 | Didier Stevens — Wednesday 27 December 2017 @ 0:00
pdf-parser in not returning an Obj ID for /Encrypt, and although not mandatory, later on pdf2john complains about an Obj id missing…
/Root 21 0 R
/Encrypt
<<
/Filter /Standard
/V 4
/CF
<<
/StdCF
<>
>>
/EncryptMetadata true
/Length 128
/R 4
/O ‘(`\xebG\x0e\xa7\xc6l\xb8\\(\xf0m\xe9\xc9\xb7\xdc\xcd\xd9\xaf3\xbd\xba\xc801\xc3O\xdf\xcbe\xd5\xe7)’
/U ‘(\xf1\xc0\x91^+:\xbc\xc1\xc0e\xa4Y\xe0\x18\xe8\x84)’
/P -1852
/StrF /StdCF
/StmF /StdCF
>>
/ID ‘[(\x93\xd2\xd4\x8aVV\xd3kC!\xe6eUs\xb7g)(\x93\xd2\xd4\x8aVV\xd3kC!\xe6eUs\xb7g)]’
/Info 23 0 R
/Size 48
Comment by PP — Wednesday 27 December 2017 @ 17:57
“patched version of pdf2john.py” – please post a link? or at least describe the fix?
Comment by Lee Wei — Wednesday 27 December 2017 @ 18:20
I did post a link: “I’m using pdf2john.py to do this.”. That is the link to the patched version.
Comment by Didier Stevens — Wednesday 27 December 2017 @ 18:22
[…] performed a brute-force attack on the password of an encrypted PDF and a brute-force attack on the key of (another) encrypted PDF, both PDFs are part of a challenge […]
Pingback by Cracking Encrypted PDFs – Part 3 | Didier Stevens — Thursday 28 December 2017 @ 0:00
@PP That is correct, in your example the encryption dictionary is not in an indirect object, but stored directly inside the trailer. The PDF language is very flexible.
And I hope you just posted an example, because with the information you published, someone can start cracking your password.
Comment by Didier Stevens — Thursday 28 December 2017 @ 21:08
[…] this is no longer the case: in this series of blog posts, I show how to recover the password, how to recover the key and how to decrypt with the key, all with free, open source […]
Pingback by Cracking Encrypted PDFs – Conclusion | Didier Stevens — Friday 29 December 2017 @ 0:00
[…] Cracking Encrypted PDFs – Part 1 […]
Pingback by Week 52 – 2017 – This Week In 4n6 — Sunday 31 December 2017 @ 0:16
[…] Cracking Encrypted PDFs – Part 1 […]
Pingback by Overview of Content Published In December | Didier Stevens — Tuesday 2 January 2018 @ 0:01
I am trying to decrypt a 256 bit encrypted pdf. I forgot the user password. All the steps up to “pdf2john.py” have worked. when I did pdf-parser, I got /Length 256. When I did python pdf2john.py “name.pdf”, I got File not Encrypted. Of course its encrypted! I need a password to open, and all previous steps have indicated that it is encrypted. Then I tried to use pdf2john.pl. I get this error
“Can’t locate ExifTool.pm in @INC (you may need to install the ExifTool module) (@INC contains: ./lib /etc/perl /usr/local/lib/x86_64-linux-gnu/perl/5.24.1 /usr/local/share/perl/5.24.1 /usr/lib/x86_64-linux-gnu/perl5/5.24 /usr/share/perl5 /usr/lib/x86_64-linux-gnu/perl/5.24 /usr/share/perl/5.24 /usr/local/lib/site_perl /usr/lib/x86_64-linux-gnu/perl-base) at pdf2john.pl line 38.
BEGIN failed–compilation aborted at pdf2john.pl line 38.”
I have no idea what this means. Is 256 encryption not supported??
Comment by Aiddog10 — Tuesday 19 June 2018 @ 22:13
By the way I am doing this on Kali Linux
Comment by Aiddog10 — Tuesday 19 June 2018 @ 22:13
Which version?
Comment by Didier Stevens — Thursday 21 June 2018 @ 11:51