TL;DR: PDFs protected with 40-bit keys can not guarantee confidentiality, even with strong passwords. When you protect your PDFs with a password, you have to encrypt your PDFs with strong passwords and use long enough keys. The PDF specification has evolved over time, and with it, the encryption options you have. There are many encryption options today, you are no longer restricted to 40-bit keys. You can use 128-bit or 256-bit keys too.
There is a trade-off too: the more advanced encryption option you use, the more recent the PDF reader must be to support the encryption option you selected. Older PDF readers are not able to handle 256-bit AES for example.
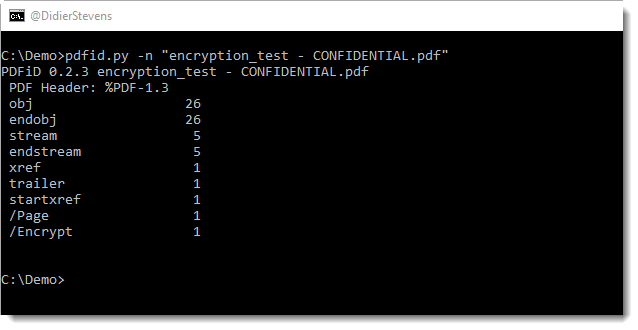
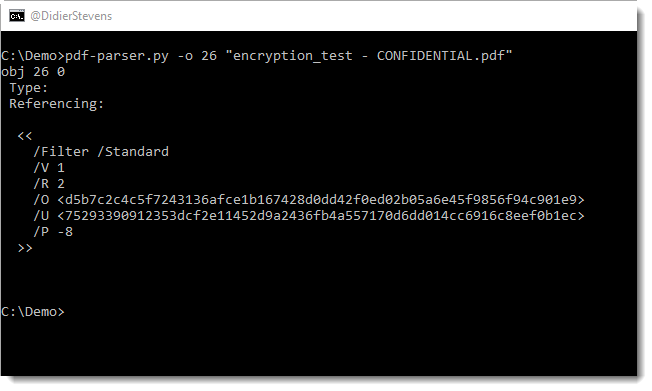
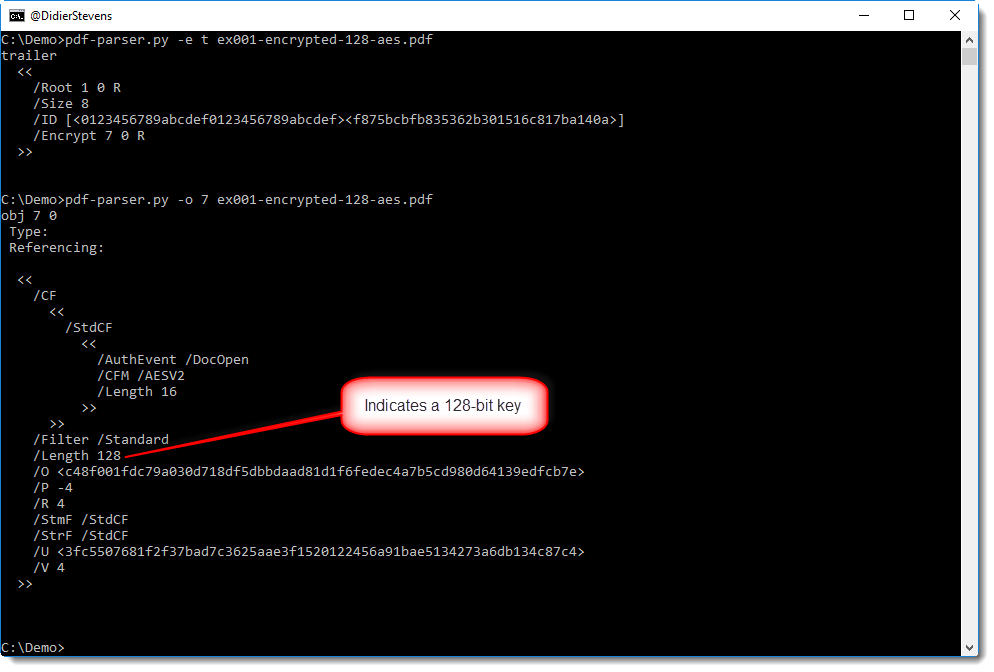
Since each application capable of creating PDFs will have different options and descriptions for encryption, I can not tell you what options to use for your particular application. There are just too many different applications and versions. But if you are not sure if you selected an encryption option that will use long enough keys, you can always check the /Encrypt dictionary of the PDF you created, for example with my pdf-parser (in this example /Length 128 tells us a 128-bit key is used):
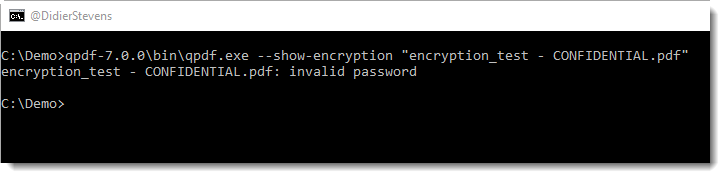
Or you can use QPDF to encrypt an existing PDF (I’ll publish a blog post later with encryption examples for QPDF).
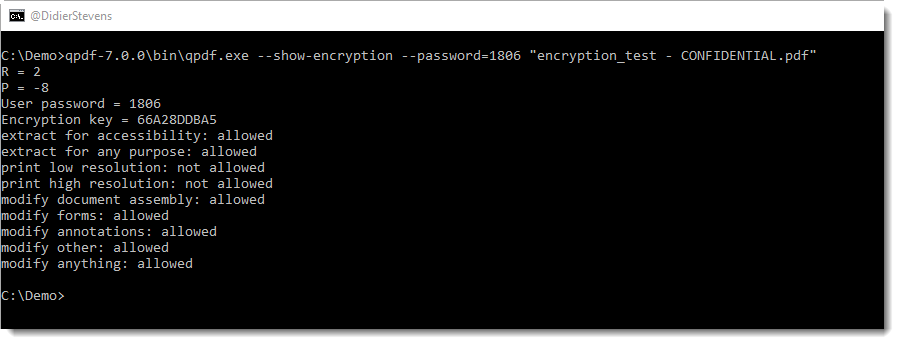
But don’t use 40-bit keys, unless confidentiality is not important to you:
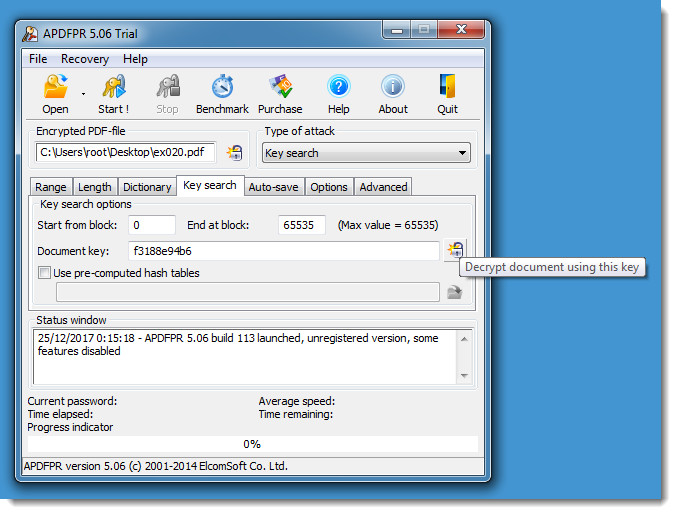
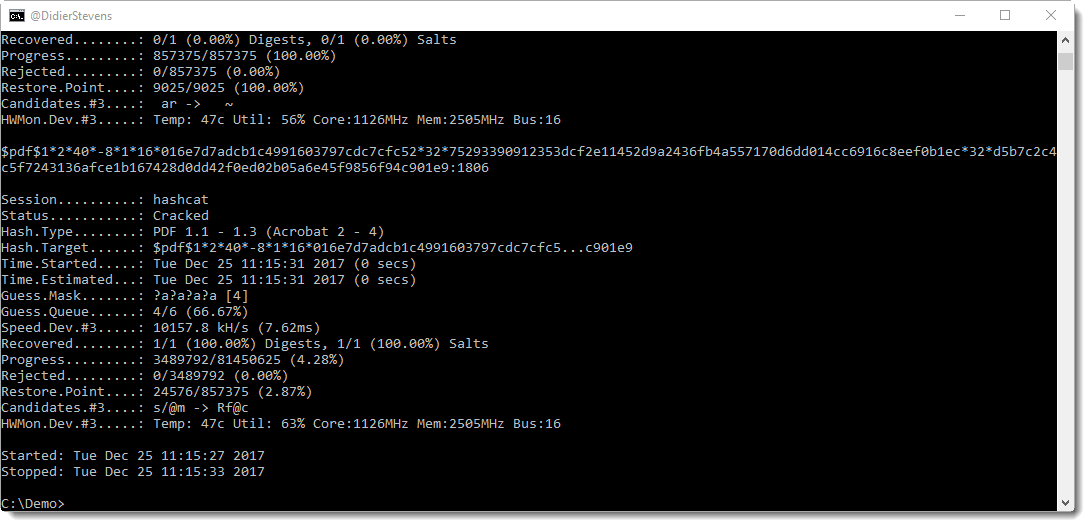
I first showed (almost 4 years ago) how PDFs with 40-bit keys can be decrypted in minutes, using a commercial tool with rainbow tables. This video illustrates this.
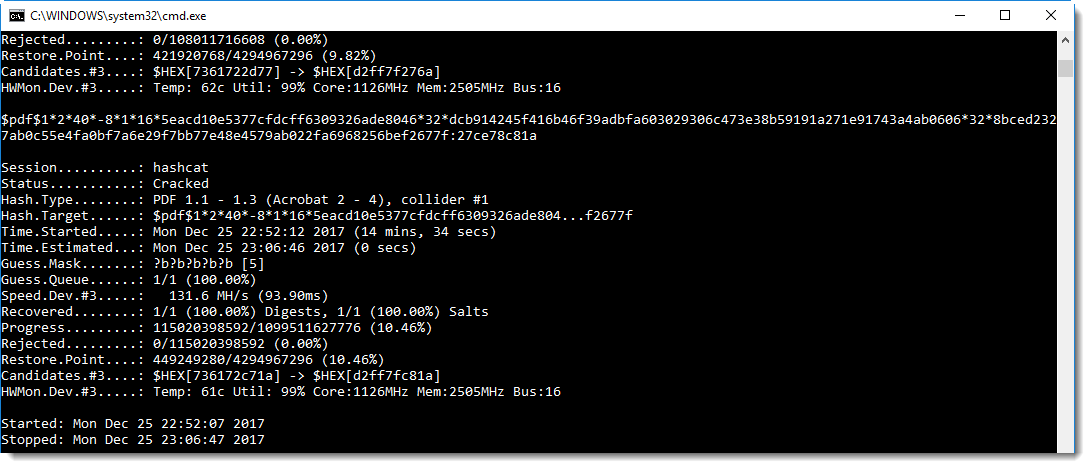
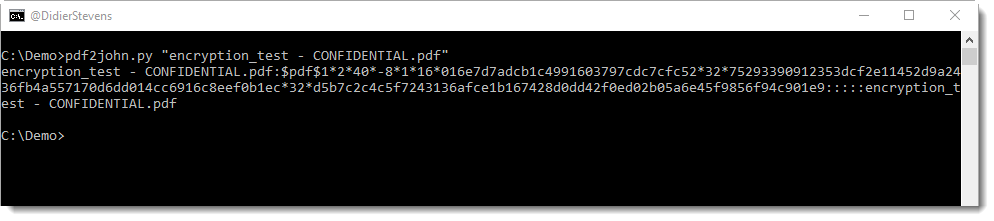
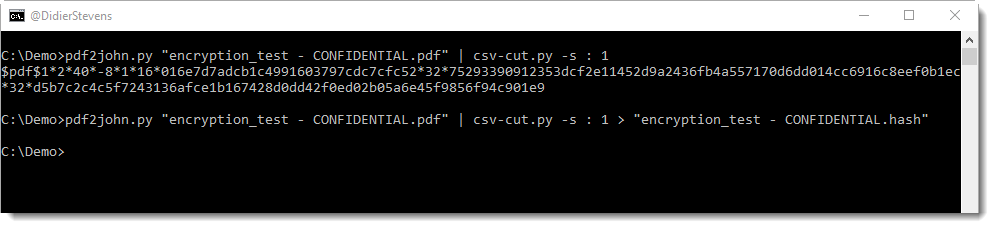
Later I showed how this can be done with free, open source tools: Hashcat and John the Ripper. But although I could recover the encryption key using Hashcat, I still had to use a commercial tool to do the actual decryption with the key recovered by Hashcat.
Today, this is no longer the case: in this series of blog posts, I show how to recover the password, how to recover the key and how to decrypt with the key, all with free, open source tools.
Overview of the complete blog post series:
-
- Cracking Encrypted PDFs – Part 1: cracking the password of a PDF and decrypting it
- Cracking Encrypted PDFs – Part 2: cracking the encryption key of a PDF
- Cracking Encrypted PDFs – Part 3: decrypting a PDF with its encryption key
- Cracking Encrypted PDFs – Conclusion: don’t use 40-bit keys (what you are reading now)