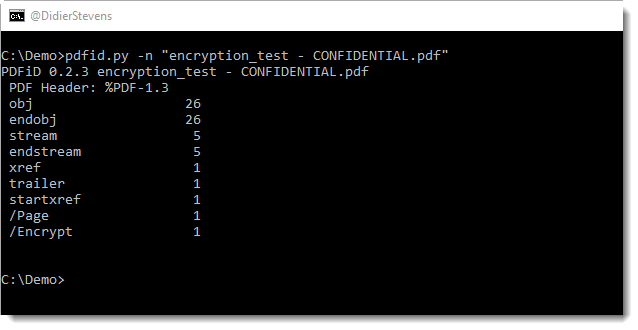
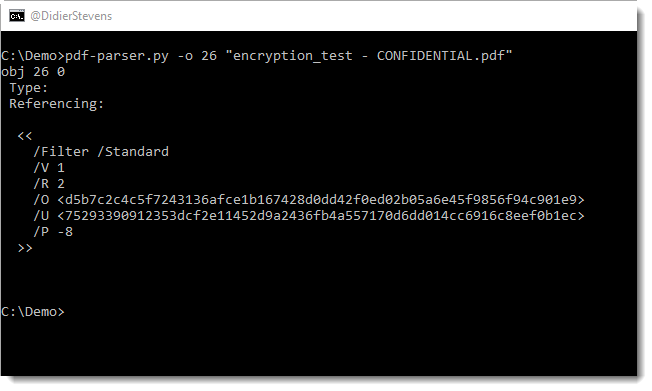
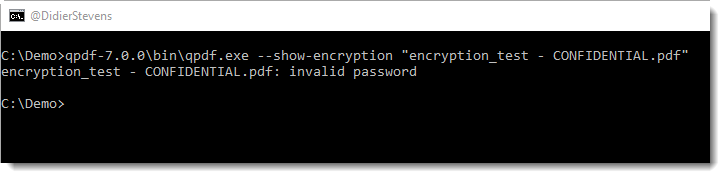
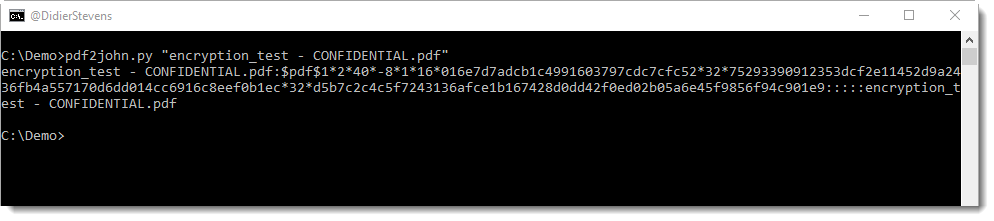
ExifTool can misidentify VBA macro files as FlashPix files.
The binary file format of Office documents (.doc, .xls) uses the Compound File Binary Format, what I like to refer as OLE files. These files can be analyzed with my tool oledump.py.
Starting with Office 2007, the default file format (.docx, .docm, .xlsx, …) is Office Open XML: OOXML. It’s in essence a ZIP container with XML files inside. However, VBA macros inside OOXML files (.docm, .xlsm) are not stored as XML files, they are still stored inside an OLE file: the ZIP container contains a file with name vbaProject.bin. That is an OLE file containing the VBA macros.
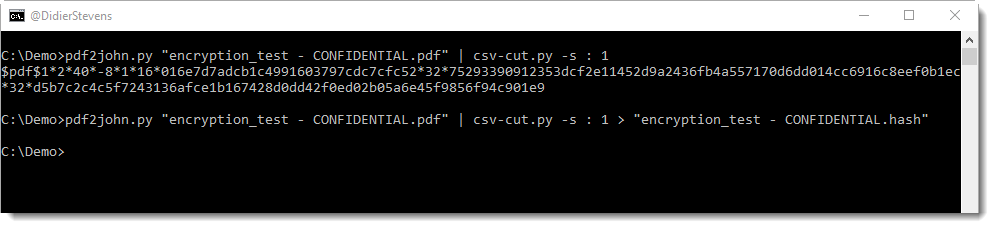
This can be observed with my zipdump.py tool:


oledump.py can look inside the ZIP container to analyze the embedded vbaProject.bin file:

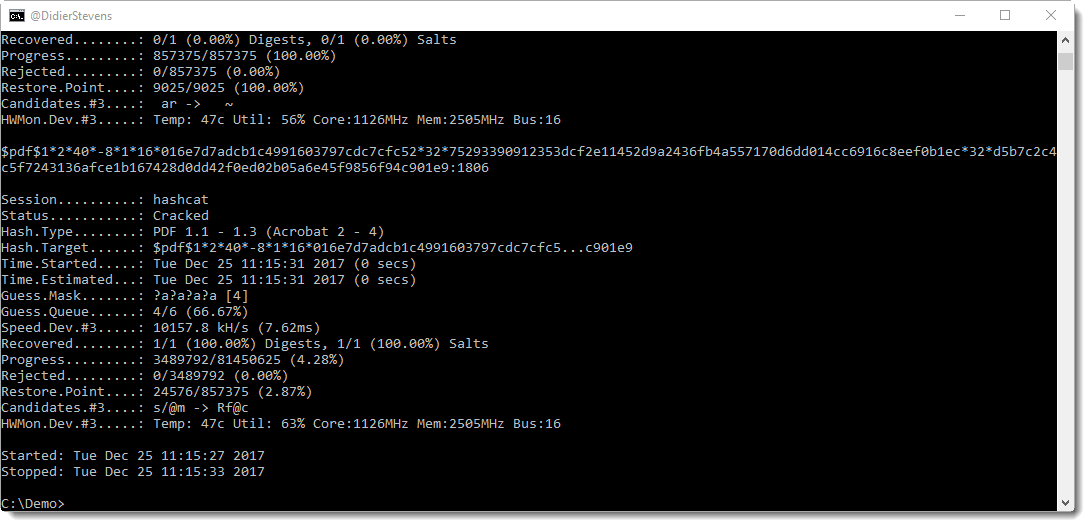
And of course, it can handle an OLE file directly:

When ExifTool is given a vbaProject.bin file for analysis, it will misidentify it as a picture file: a FlashPix file.

That’s because when ExifTool doesn’t have enough metadata or an identifying extension to identify an OLE file, it will fall back to FlashPix file detection. That’s because FlashPix files are also based on the OLE file format, and AFAIK ExifTool started out as an image tool:

That is why on VirusTotal, vbaProject.bin files from OOXML files with macros, will be misidentified as FlashPix files:

When the extension of a vbaProject.bin file is changed to .doc, ExifTool will misidentify it as a Word document:

ExifTool is not designed to identify VBA macro files (vbaProject.bin). These files are not Office documents, neither pictures. But since they are also OLE files, ExifTool tries to guess what they are, based on the extension, and if that doesn’t help, it falls back to the FlashPix file format (based on OLE).
There’s no “bug” to fix, you just need to be aware of this particular behavior of ExifTool: it is a tool to extract information from media formats, when it analyses an OLE file and doesn’t have enough metadata/proper file extension, it will fall back to FlashPix identification.