This new version supports different encodings besides base64 (but the name remains base64dump).
The new encodings are hexadecimal (hex), \u unicode (bu) and %u unicode (pu).
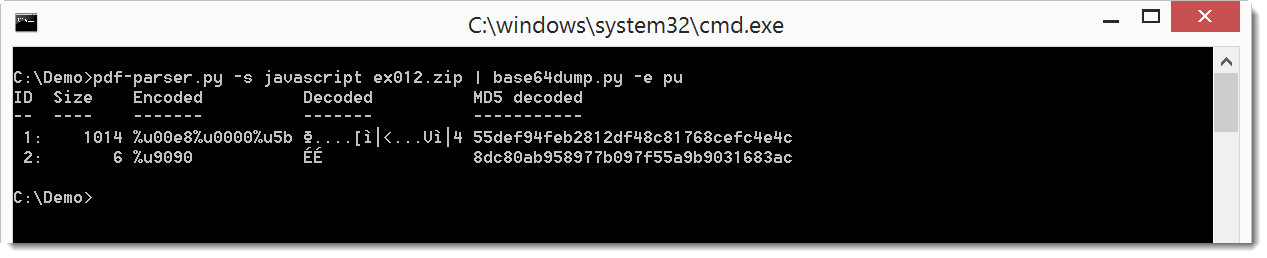
Here’s an example with escaped unicode in JavaScript (%u), namely a PDF with shellcode in JavaScript:

The shellcode, escaped with %u, can be extracted with base64dump:

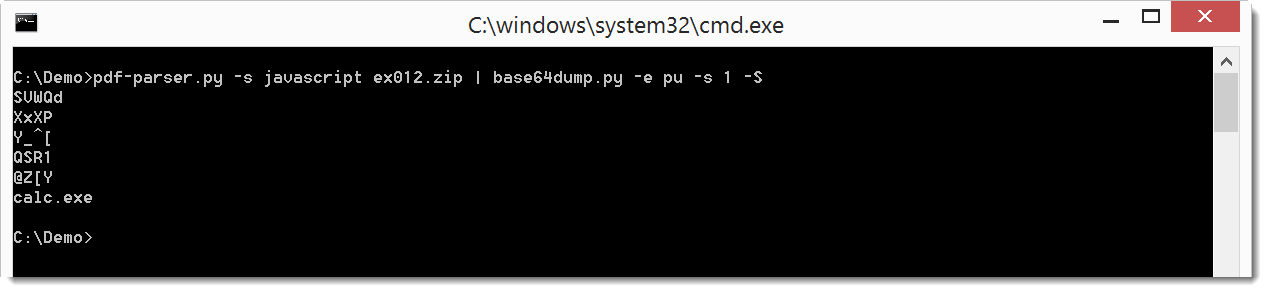
There’s also a new option to do a string dump: -S
And a last small update: this version also counts unique bytes, i.e. the number of different byte values found in the data.
base64dump_V0_0_5.zip (https)
MD5: 7AACFD3E34FEAAF41897F60FBC5279A3
SHA256: B4AB7B3A9D2947F08C6CC94F88CD825C9B2B63EE65AF7475E66BE9565EC4337A

[…] Didier Stevens updated his base64dump Python script to version 0.0.5 to support additional encodings (hexadecimal (hex), u unicode (bu) and %u unicode (pu)) Update: base64dump.py Version 0.0.5 […]
Pingback by Week 47 – 2016 – This Week In 4n6 — Saturday 26 November 2016 @ 23:04
[…] Update: base64dump.py Version 0.0.5 […]
Pingback by Overview of Content Published In November | Didier Stevens — Tuesday 6 December 2016 @ 0:00
[…] The data field looks like BASE64, so let’s try to decode it with base64dump.py: […]
Pingback by Quickpost: Dropbox & Alternate Data Streams | Didier Stevens — Monday 30 January 2017 @ 0:00
[…] base64dump.py is a tool to search for BASE64 strings (and other encodings like hexadecimal). We will use it to search for a payload in the EPS file. Since the file is large, we can expect to have a lot of hits. So let’s set a minimum sequence length of 1000: […]
Pingback by Maldoc: It’s not all VBA these days | NVISO LABS – blog — Wednesday 8 February 2017 @ 9:04