About a week ago, I was asked if I had tools for OneNote files.
I don’t, and I had no time to take a closer look.
But last Thursday night, I had some time to take a look. I looked at this OneNote maldoc sample.
I opened the file in the binary editor I use often (010 Editor):
I expected to see some magic header, a special sequence of byte that would tell me which file type is used. I didn’t see that, but I noticed that the first 16 bytes look random. And they were the same for another sample. So this could be a GUID. GUIDs in Microsoft’s representation are a mix of little- and big-endian hexadecimal integers. That’s why 010 Editor has an entry for GUIDs in its inspector tab:
This is the GUID represented as a string: {7B5C52E4-D88C-4DA7-AEB1-5378D02996D3}
Looking this up with Google:
That’s great, Microsoft has a document [MS-ONESTORE] describing this file format.
Unfortunately, I did a quick search but didn’t find a pure Python module to read this file format. Maybe it exists, but I didn’t find it.
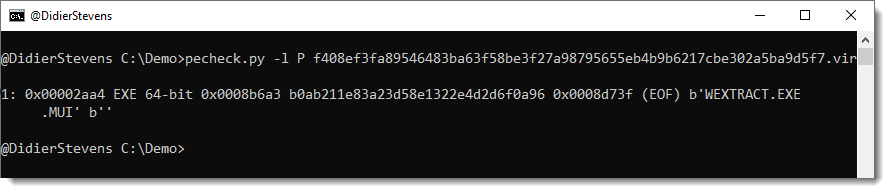
Next I tried my pecheck.py tool to locate the executable inside the onenote sample. That worked well:
At position 0x2aa4, here’s an embedded PE file. Taking a look with the binary editor:
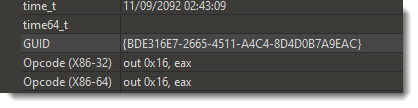
I see the MZ header, and 36 bytes in front of that, another random looking sequence of 16 bytes. Maybe another GUID:
So looking for this GUID in any file, one can find (and extract) embedded files. So that’s what I quickly coded using my Python template for binary files (there are some issues with this GUID-search method, I’ll address these in an upcoming blog post or video)
I let it produce JSON output using option –jsonoutput, that can be consumed by some of my tools, like file-magic.py, my tool to identify files based on the content using the libmagic library.
In the output above, we can see that most files are PE files (Windows executables).
For this example, I’m interested in Office files (ole files). I can filter the output of file-magic.py for that with option -r. Libmagic identifies this type of file as “Composite Document File …”, thus I filter for Composite:
This gives me a list of malicious Office documents. I want to extract URLs from them, but I don’t want to extract all of these files from the ZIP container to disk, and do the URL extraction file per file.
I want to do this with a one-liner. 🙂
What I’m going to do, is use file-magic’s option –jsonoutput, so that it augments the json output of zipdump with the file type, and then I use my tool myjson-filter.py to filter that json output for files that are only of a type that contains the word Composite. With this command:
This produces JSON output that contains the content of each file of type Composite, found inside the ZIP container.
This output can be consumed by my tool strings.py, to extract all the strings.
Side note: if you want to know first which files were selected for processing, use option -l:
Let’s pipe the filtered JSON output into strings.py, with options to produce a list of unique strings (-u) that contain the word http (-s http), like this:
I use my tool re-search.py to extract a list of unique URLs:
I filter out common URLs found in Office documents:
And finally, I sort the URLs by domain name using my tool sortcanon.py:
The adobe URLs are not malicious, but the other ones could be.
This one-liner allows me to quickly process daily malware batches, looking for easy IOCs (cleartext URLs in Office documents) without writing any malicious file to disk.
Remark that by using an option to search for strings with the word http (-s http), I reduce the output of strings to be processed by re-search.py, so that the search is faster. But that limits you (mostly) to URLs with protocol http or https.
Leave out this option if you want to search for all possible protocols, or try -s “://”.