The malicious office document we’re analyzing is a downloader: 0e73d64fbdf6c87935c0cff9e65fa3be
oledump reveals VBA macros in the document, but the plugins are not able to extract a URL:
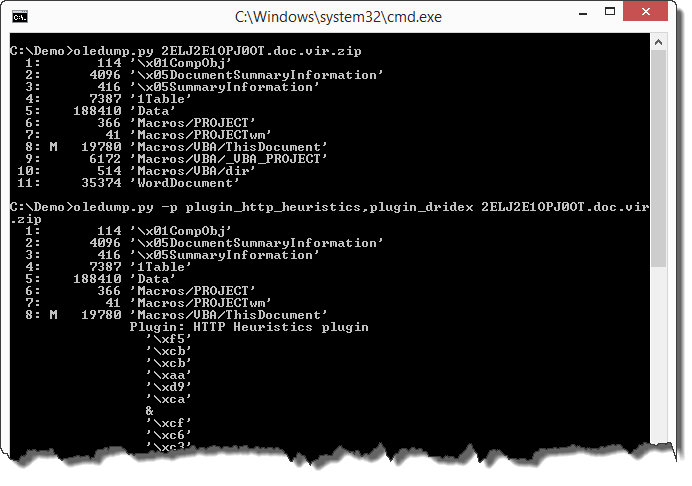
Let’s use a new plugin that I wrote: plugin_vba_dco. This plugin searches for Declare statements and CreateObject calls:

In the first half of the output (1) we see all lines containing the Declare or CreateObject keyword. In the second half of the output (2) we see all lines containing calls to declared functions or created objects.
Although the code is obfuscated (obfuscation of strings and variable names), the output of this plugin allows us to guess that Ci8J27hf2 is probably a XMLHTTP object, because of the .Open, .send, .Status, … methods and properties.
The Open method of the XMLHTTP object takes 3 parameters: the HTTP method, the URL and a boolean (asynchronous or synchronous call):
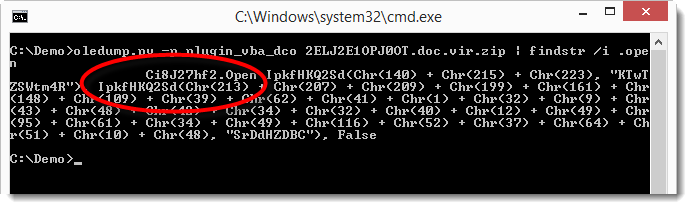
As we can see, the third parameter is False and the first 2 parameters are the return value of a function called IpkfHKQ2Sd. This function takes 2 parameters: 2 strings. The first string is the result of concatenated Chr functions, and the second string is a literal string. Since the Open method requires the HTTP method and URL as strings, is very likely that function IpkfHKQ2Sd is a decoding function that takes 2 strings as input (meaningless to us) and returns a meaningful string.
Here is the original IpkfHKQ2Sd function. It’s heavily obfuscated:

Here is the same function that I deobfuscated. I didn’t change the function name, but I removed all useless code, renamed variables and added indentation:

We can now see that this function uses a key (sKey) and XOR operations to decode a secret string (sSecret). And now we can also see that this is just a string manipulation function. It does not contain malicious or dangerous statements or function calls. So it is safe to use in a VBA interpreter, we don’t need to translate it into another language like Python.
We are going to use this deobfuscated function in a new spreadsheet to decode the URL parameter:

In the VBA editor of this new spreadsheet, we have the deobfuscated IpkfHKQ2Sd function and a test subroutine that calls the IpkfHKQ2Sd function with strings that we found in the .Open method for the URL argument. The decoded string returned by function IpkfHKQ2Sd is displayed via MsgBox. Executing this test subroutine reveals the URL:

Downloading this file, we see it’s not a JPEG file, but contrary to what we could expect, it’s neither an EXE file:

Searching for .responseBody in the VBA code, we see that the downloaded file (present in .responseBody) is passed as an argument to function IpkfHKQ2Sd:

This means that the downloaded file is also encoded. It needs to be decoded with the same function as we used for the URL: function IpkfHKQ2Sd (but with another key).
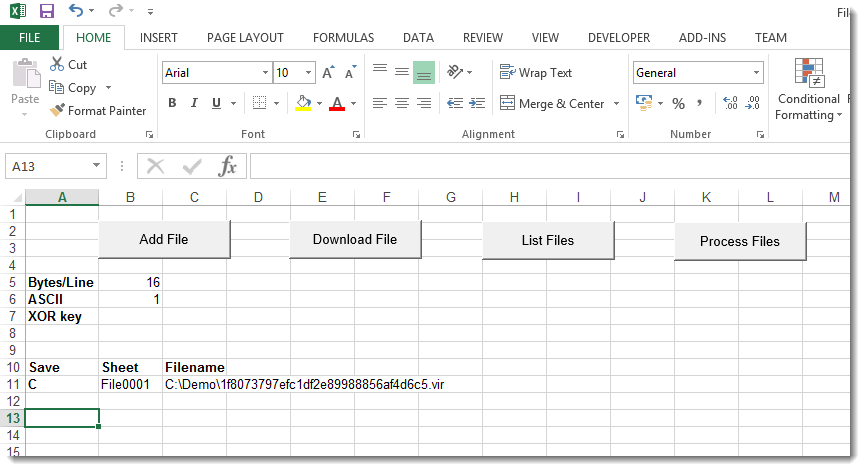
To convert this file with the deobfuscated function in our spreadsheet, we need to load the file in the spreadsheet, decode it, and save the decoded file to disk. This can be done with my FileContainer.xls tool (to be released). First we load the encoded file in the FileContainer:


FileContainer supports file conversion: we have to use command C and push the Process Files button:
Here is the default conversion function Convert. This default function doesn’t change the file: the output is equal to the input:

To decode the file, we need to update the Convert function to call the decoding function IpkfHKQ2Sd with the right key. Like this:

And then, when we convert the file, we obtain an EXE file:

This EXE turns out to be Dridex malware: 50E3407557500FCD0D81BB6E3B026404
Remark: reusing code from malware is dangerous unless we know exactly what the code does. To decode the downloaded file quickly, we reused the decoding VBA function IpkfHKQ2Sd (I did not translate it into another language like Python). But to be sure it was not malicious, I deobfuscated it first. The deobfuscation process gave me the opportunity to look at each individual statement, thereby giving me insight into the code and come to the conclusion that this function is not dangerous. We could also have used the obfuscated function, but then we ran the risk that malware would execute because we did not fully understand what the obfuscated function did.
Translating the obfuscating function to another language doesn’t make it less dangerous, but it allows us to execute it in a non-Windows environment (like Linux), thereby preventing Windows malware from executing.










