Isn’t the beginning of a new year a good moment to release a new tool called what-is-new.py? 🙂
It’s actually an old tool, I started this in 2012, because it’s something I have to do often: I have a recurring list, and I need to know what items on that list are new (in a nutshell, that’s the problem I tried to solve).
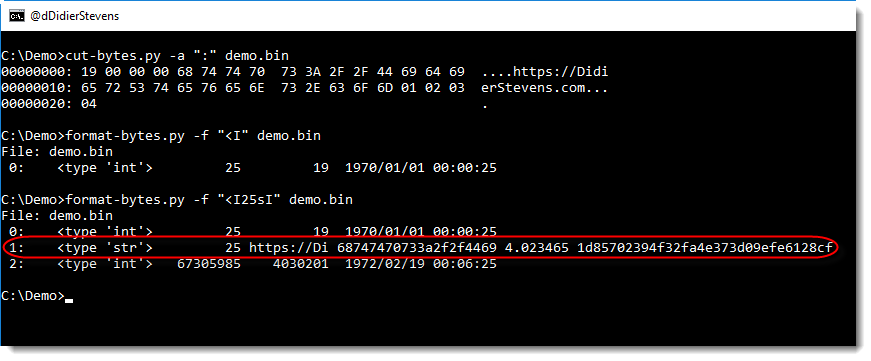
For example, every week I produce a list of User Agent Strings for the requests to my web servers. With a single what-is-new.py command, I can see what User Agent Strings have never hit my servers before.
what-is-new.py takes one argument and a bunch of files. The argument is the name of the database (a Python pickle file). The input can be a single file, several files or stdin. Every line in these files that was not seen before (i.e. not in the database) will be listed by what-is-new.py
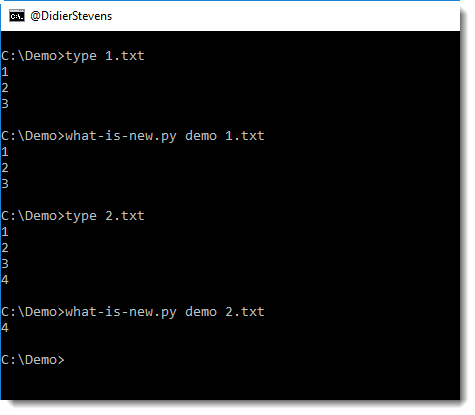
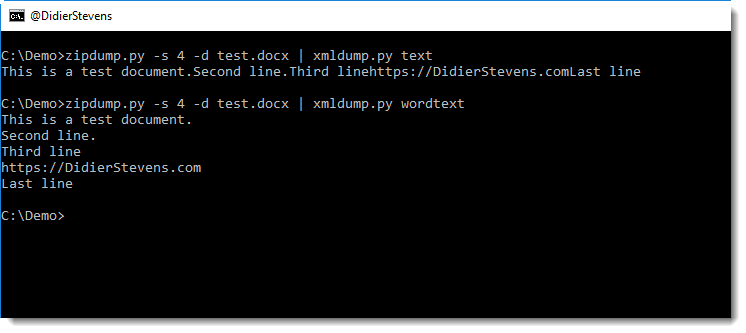
In the following example, I run 2 files through what-is-new (files 1.txt and 2.txt) with database demo. The database doesn’t exist yet, hence all lines of the first file are considered new. But with the second invocation, you can see that only line 4 is new.

The tool has several options, I invite you to take a look at the help (-h) and manual (-m).
what-is-new_V0_0_1.zip (https)
MD5: 02067A60EA2EBEE29E98CAF31CEDDF37
SHA256: A4499A230D1925C164531A68C0E8F4FE016882A44D6EDBFF9F4D7BFFA29D14A4