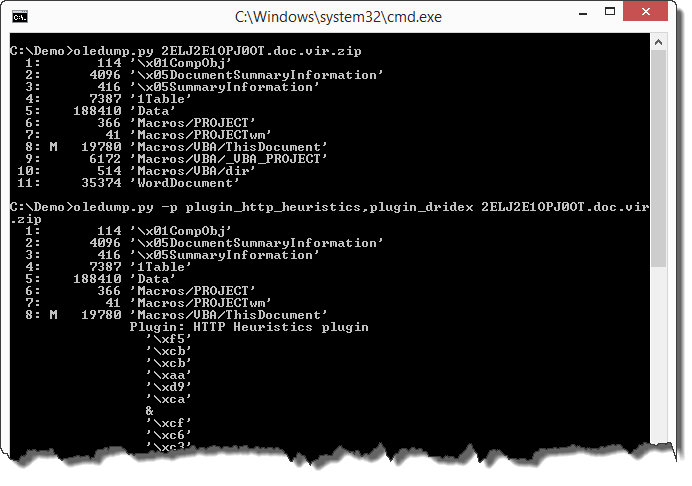
Option -c calculates extra data per stream. This data is displayed per stream. Only the MD5 hash of the content of the stream is calculated.
Example:
C:\Demo>oledump.py -c Book1.xls
1: 4096 ‘\x05DocumentSummaryInformation’ ff1773dce227027d410b09f8f3224a56
2: 4096 ‘\x05SummaryInformation’ b46068f38a3294ca9163442cb8271028
3: 4096 ‘Workbook’ d6a5bebba74fb1adf84c4ee66b2bf8dd
In stead of adding more calculations to option -c, I added option -E (extra) which allows the user to specify which extra info needs to be displayed. From the man page:
If you need more data than the MD5 of each stream, use option -E
(extra). This option takes a parameter describing the extra data that
needs to be calculated and displayed for each stream. The following
variables are defined:
%INDEX%: the index of the stream
%INDICATOR%: macro indicator
%LENGTH%': the length of the stream
%NAME%: the printable name of the stream
%MD5%: calculates MD5 hash
%SHA1%: calculates SHA1 hash
%SHA256%: calculates SHA256 hash
%ENTROPY%: calculates entropy
%HEADHEX%: display first 20 bytes of the stream as hexadecimal
%HEADASCII%: display first 20 bytes of the stream as ASCII
%TAILHEX%: display last 20 bytes of the stream as hexadecimal
%TAILASCII%: display last 20 bytes of the stream as ASCII
%HISTOGRAM%: calculates a histogram
this is the prevalence of each byte value (0x00 through 0xFF)
at least 3 numbers are displayed separated by a comma:
number of values with a prevalence > 0
minimum values with a prevalence > 0
maximum values with a prevalence > 0
each value with a prevalence > 0
%BYTESTATS%: calculates byte statistics
byte statistics are 5 numbers separated by a comma:
number of NULL bytes
number of control bytes
number of whitespace bytes
number of printable bytes
number of high bytes
The parameter for -E may contain other text than the variables, which
will be printed. Escape characters \n and \t are supported.
Example displaying the MD5 and SHA256 hash per stream, separated by a
space character:
C:\Demo>oledump.py -E "%MD5% %SHA256%" Book1.xls
1: 4096 '\x05DocumentSummaryInformation' ff1773dce227027d410b09f8f3224a56 2817c0fbe2931a562be17ed163775ea5e0b12aac203a095f51ffdbd5b27e7737
2: 4096 '\x05SummaryInformation' b46068f38a3294ca9163442cb8271028 2c3009a215346ae5163d5776ead3102e49f6b5c4d29bd1201e9a32d3bfe52723
3: 4096 'Workbook' d6a5bebba74fb1adf84c4ee66b2bf8dd 82157e87a4e70920bf8975625f636d84101bbe8f07a998bc571eb8fa32d3a498
If the extra parameter starts with !, then it replaces the complete
output line (in stead of being appended to the output line).
Example:
C:\Demo>oledump.py -E "!%INDEX% %MD5%" Book1.xls
1 ff1773dce227027d410b09f8f3224a56
2 b46068f38a3294ca9163442cb8271028
3 d6a5bebba74fb1adf84c4ee66b2bf8dd
To include extra data with each use of oledump, define environment
variable OLEDUMP_EXTRA with the parameter that should be passed to -E.
When environment variable OLEDUMP_EXTRA is defined, option -E can be
ommited. When option -E is used together with environment variable
OLEDUMP_EXTRA, the parameter of option -E is used and the environment
variable is ignored.
oledump_V0_0_20.zip (https)
MD5: 715B33E8E090F2A061DB2EA5A913055F
SHA256: 056CC911AEDFFB48B756F1B941E14660EBA8B613C65B1026F5DA77FB3047DAE3