I’m quite pleased with the feedback I received for my Little PDF Puzzle, thanks all.
As promised, I’m posting the solution now, but first be sure you understand the basic structure of a PDF file.
The PDF file format supports Incremental Updates, this means that changes to an existing PDF document can be appended to the end of the file, leaving the original content intact. When the PDF file is rendered by a PDF reader, it will display the latest version, not the original content. Remember that the basic structure of a PDF file (one without incremental updates) consists of 4 parts:
- header
- objects
- cross reference table
- trailer
A PDF file with one incremental update has the following structure:
- header
- objects (original content)
- cross reference table (original content)
- trailer (original content)
- objects (updated content)
- cross reference table (updated content)
- trailer (updated content)
Every object that has been modified can be found twice in the PDF file. The unmodified object is still present in the original content, and the edited version of the same object can be found in the updated content.
The cross reference table of the updated content indexes the updated objects, and the trailer of the updated content points to both cross reference tables.
When a PDF reader renders a PDF document, it starts from the end of the file. It reads the last trailer and follows the links to the root object and the cross reference tables to build the logical structure of the document it is about to render. When the reader encounters updated objects, it ignores the original versions of the same objects.
Let’s open our PDF Puzzle with a PDF reader:
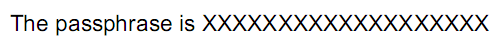
And let’s also open it with Notepad:

With Notepad, it becomes clear that I’ve created a PDF document with an incremental update (original document in red, update in blue). If you delete the updated content (the blue part, or everything after the first occurrence of %%EOF), you’ve actually recovered the original version. Save it and open it with your PDF reader:

In the original PDF document, I stored the sentence “The passphrase is Incremental Updates” in indirect object 5 (to make the puzzle a bit more challenging, I used an ASCII85 encoded stream, otherwise you could just read the solution with Notepad). Next, I updated the sentence to “The passphrase is XXXXXXXXXXXXXXXXXXX” by creating a new version of object 5 and appending this at the end of the original PDF document. To finalize the updated document, I added a new cross reference table (just indexing the new version of object 5) and a new trailer (referencing the new and the old cross reference tables).
If you produce PDF documents with a PDF editor that supports incremental updates, be aware that previous versions of your document could be included in the final document, and that this could lead to information disclosure. Most office applications that support export to PDF do not use incremental updates (because they save the document in their own native format, not PDF).
If you conduct forensic investigations or do malware research, don’t limit your analysis to the final version of a PDF document. You can easily identify incrementally updated PDF documents by looking for multiple instances of cross reference tables and trailers. But don’t get confused by Linearized PDF documents, they too have more than one cross reference table and trailer (linearized PDF documents start with an indirect object sporting a /Linearized name).
You can find interesting information in the different versions included in an incremental PDF file. For example, I have a malicious PDF sample that has been created in February 2008, updated in March 2008 to add the malicious payload (it took the author about 20 minutes) and, not surprising, that this was done on a machine with the timezone set to GMT+08.
A final detail: to allow you to edit the PDF puzzle with Notepad, I produced an ASCII-only PDF file (that’s one of the reasons I used ASCII85 encoding for the stream of indirect object 5). But most PDF documents contain non-ASCII characters, so be sure to use an editor that will support this (and that won’t convert 0x0A or 0x0D to 0x0D0A).
