VBA projects can be protected with a password. The password is not used to encrypt the content of the VBA project, it is just used as protection by the VBA IDE: when the password is set, you will be prompted for the password.
Tools like oledump.py are not hindered by a VBA password, they can extract VBA code without problem, as it is not encrypted.
The VBA password is stored as the DPB value of the PROJECT stream:


You can remove password protection by replacing the values of ID, CMG, DPB and GC with the values of an unprotected VBA Project.
Thus a VBA password is no hindrance for staticanalysis.
However, we might still want to recover the password, just for the fun of it. How do we proceed?
The password itself is not stored inside the PROJECT stream. In stead, a hash is stored: the SHA1 hash of the password (MBCS representation) + 4 byte salt.
Then, this hash is encrypted (data encryption as described in MS-OVBA 2.4.3.2) and the hexadecimal representation of this encrypted hash is the value of DPB.
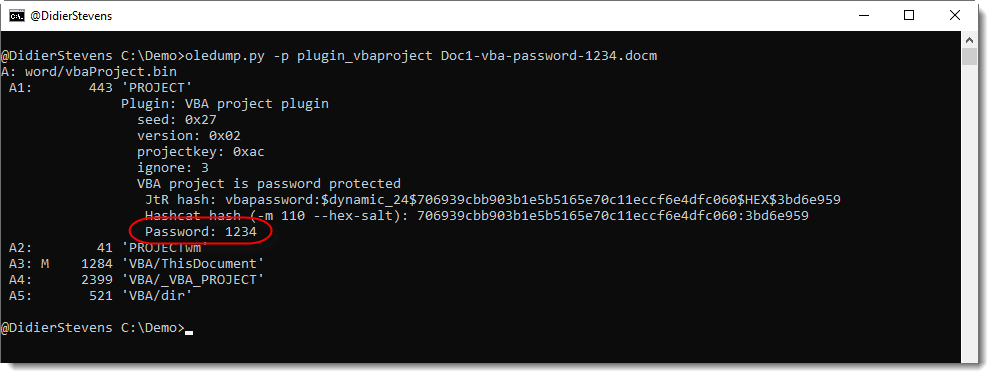
This data encryption is done according to an algorithm that does not use a secret key. I wrote an oledump.py plugin (plugin_vbaproject.py) to decrypt the hash and display it in a format suitable for John the Ripper and Hashcat:
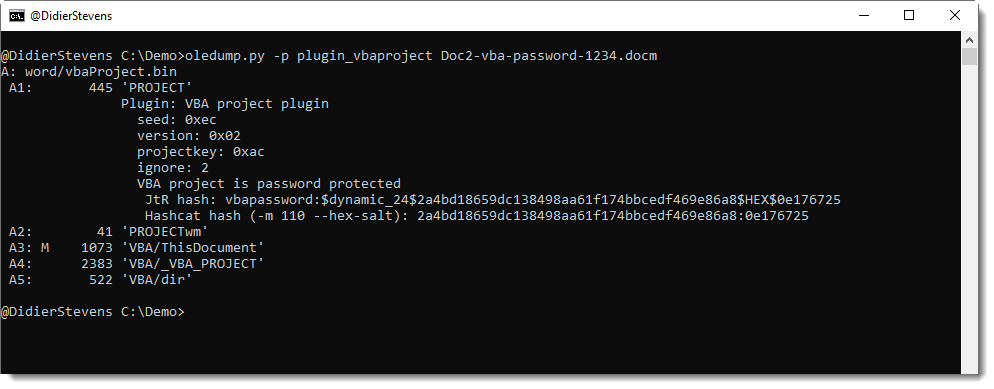
The SHA1 of a password + salt is a dynamic format in John the Ripper: dynamic_24.

For Hashcat, it is mode 110 and you also need to use option –hex-salt.

Remark that the password passed as argument to the SHA1 function is represented in Multi Byte Character Set format. This means that ASCII characters are represented as bytes, but that non-ASCII characters might be represented with more than one byte, depending on the VBA project’s code page.