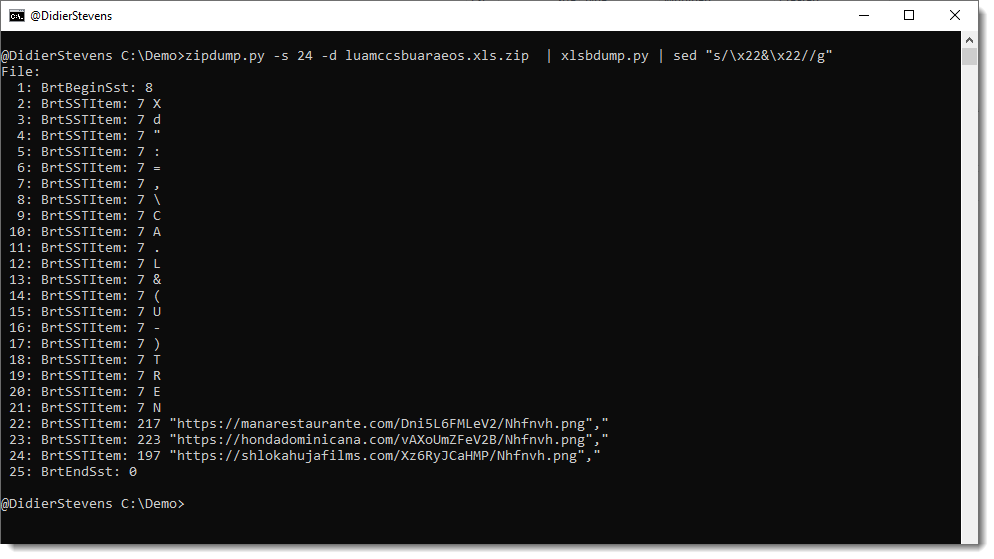
This is just a bugfix version.
zipdump_v0_0_22.zip (http)MD5: 68F9F3809E4E1F9ADE4A4C3835CDF475
SHA256: 92ED372579001C826D5AF31615B8334CC798FF2DA4AF8B7C46267BF7D995C757
This is just a bugfix version.
zipdump_v0_0_22.zip (http)In this update for cs-parse-traffic.py, my tool to decrypt & parse Cobalt Strike traffic, I added some error handling.
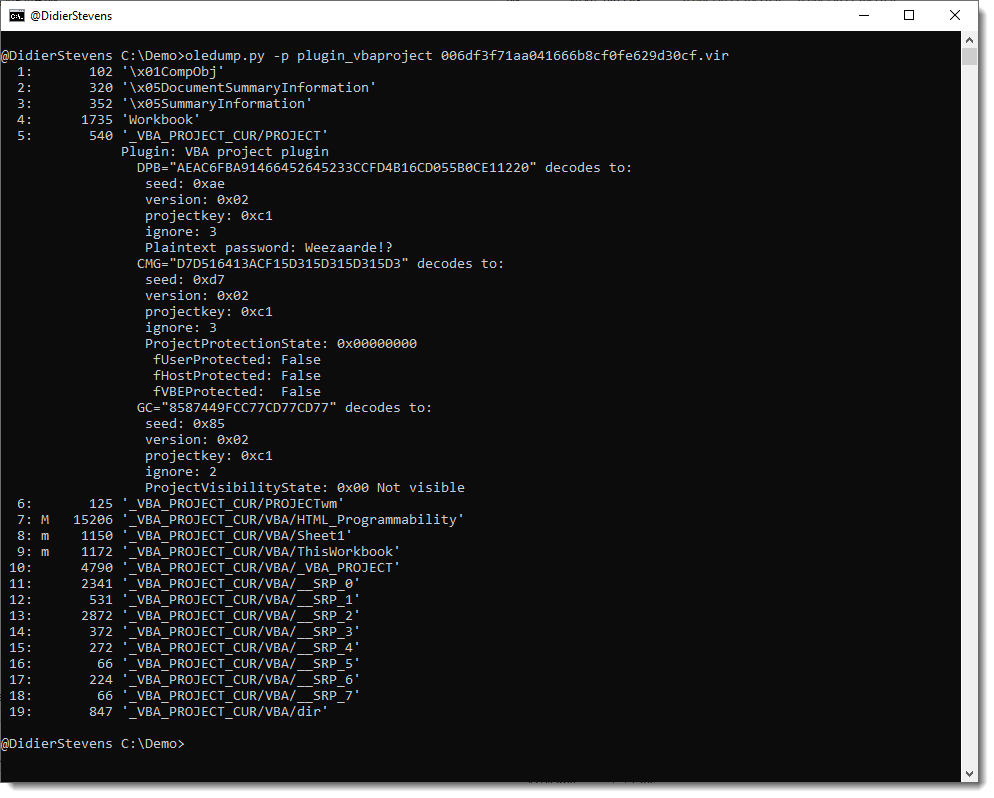
cs-parse-traffic_V0_0_5.zip (http)This new version of oledump.py brings some fixes and an update to plugin plugin_vbaproject to decode and display the password for plaintext passwords:


This new version of oledump.py brings a new plugin (plugin_metadata) and Python 3 fixes for 2 plugins (plugin_msi and plugin_ppt).
The new plugin is actually an old unpublished plugin, that I updated recently.
This plugin parses Office document metadata as defined in document [MS-OLEPS].
I started to write this in 2015 to parse the metadata of Word documents, but soon I figured out that this functionality was already present in olefile, and I introduced option -M to call this functionality.
But recently, I had to parse metadata that isn’t (yet) parsed by olefile, so I updated and released plugin_metadata.
oledump_V0_0_65.zip (http)This is a Python3 stdin fix for re-search.py, my tool to search with regular expressions.
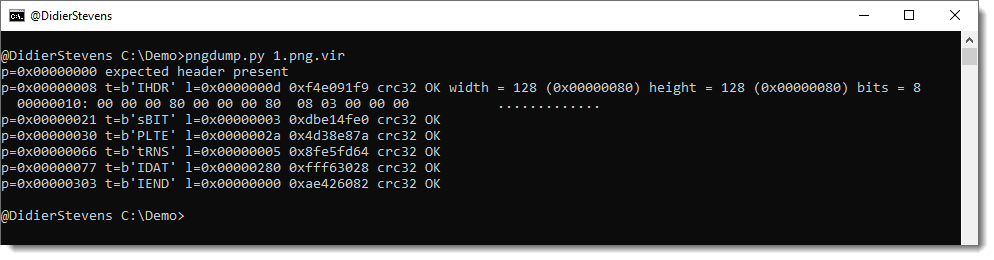
re-search_V0_0_19.zip (http)Here is a new tool I’m releasing as beta: pngdump.py.
It’s a tool to analyze PNG files. Unlike jpegdump, you can not yet select items for further analysis.
This new version of 1768.py brings option -H to include file hashes, introduces shellcode type detection and has updated statistics.

This new version of cut-bytes.py adds access to the read data for Python expressions in prefix and suffix options.
cut-bytes_V0_0_14.zip (http)A couple of my tools can produce JSON output, using my own format (myjson).
This output can then be piped into another tool, like strings.py or file-magic.py.
I’m now releasing a tool that can be put into a command pipe to filter the JSON data: myjson-filter.py
For example, here I use myjson-filter.py to remove all items that are XML files (based on the content: starting with <?xml) before strings are extracted with strings.py:
More info in this ISC diary entry I wrote: “Method For String Extraction Filtering“.