I regularly get ideas to improve my tools when I give (private) training, and last week was not different.
This new version of pdfid.py adds a /URI counter, to help identify PDF documents with embedded URLs, used for phishing or social-engineering users into clicking on links.
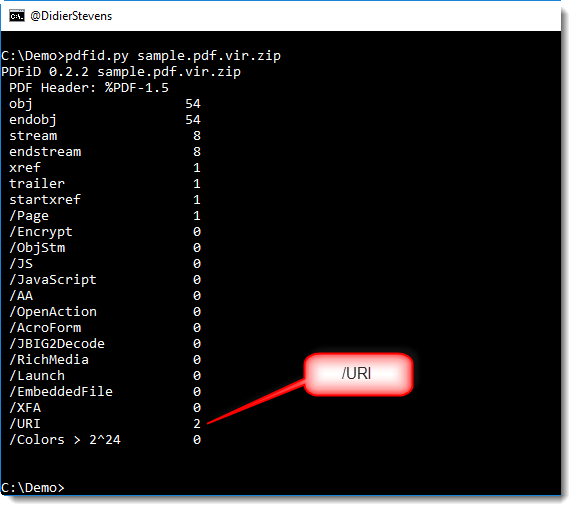
I did not hardcode this new counter into the source code of pdfid.py, but it is listed in a new config file: pdfid.ini. You too can add your own identifiers to this configuration file.
pdfid_v0_2_2.zip (https)
MD5: 20614B44D97D48813D867AA8F1C87D4E
SHA256: FBF668779A946C70E6C303417AFA91B1F8A672C0293F855EF85B0E347D3F3259

[…] Update: pdfid.py Version 0.2.2 […]
Pingback by Overview of Content Published In October | Didier Stevens — Wednesday 1 November 2017 @ 0:00
[…] Update: pdfid.py Version 0.2.2 […]
Pingback by Week 44 – 2017 – This Week In 4n6 — Sunday 5 November 2017 @ 9:01
[…] after confirming it as a PDF file, the next step is always to use the tool PDFiD from Didier Stevens, with the plugin_triage option, to determine in a quick way if the document contains suspicious […]
Pingback by Checking for maliciousness in Acroform objects on PDF files – Furoner.CAT — Wednesday 15 November 2017 @ 15:21
Dear Sir,I’m a Chinese junior student over the “China Tall” …Recently,I’ve been working on pdf document security detection.And I find handy pdfid and pdf-parser tool on your blog.Here is one of my questions:pdfid.py can get names from pdf file (even all by using -a). What I want to do is to get all the related names which are pdf offcial key name(I can’t say the exact expression).But “-a” will extrat all the names included like /a /aa /aaa /aaa etc.These have no research value.I want find a set of all pdf offcial key name,but I couldn’t find it.Can I use pdfid to solve this problem.Appreciate your precious answer.Many thanks!!!
Comment by Anonymous — Sunday 4 February 2018 @ 7:13
You can find this in the pdf reference manual https://www.adobe.com/content/dam/acom/en/devnet/pdf/pdfs/PDF32000_2008.pdf
Comment by Didier Stevens — Sunday 4 February 2018 @ 19:45
Dear Sir,I feel very lucky and surprised to get your real reply.It’s just like I encounter a big star and get his signature. Actually I’ve got the ”pdf reference” before. I’ve browsed it and found that the key names scatter around the whole book .So the set of all official key name is hard to get by this way.As you recommend,I read “pdf reference” again.This time,I find “Name Registry” in Chapter “Annex E”.It seems like the website”http://adobe.com/go/ISO32000Registry” has the list of all official key name(in Adobe term,may be the first class name).But now the website is not available anymore.May you give me more details?Many thanks again!!!
Comment by Anonymous — Monday 5 February 2018 @ 5:51
If you can’t find the site on the Internet, it’s best to get in touch with Adobe. Another option is to check the latest version of the PDF reference document, but that is not free.
Comment by Didier Stevens — Tuesday 6 February 2018 @ 9:57
I’ve got it. Thanks for your precious reply.And in Chinese net words,I’d prefer to say “比心”(bi’xin) to express my gratitude.比心!!!
Comment by Anonymous — Tuesday 6 February 2018 @ 14:17
Dear Sir,
sorry to bother you again ;(. This time issue is still about pdf key word detecting.
I have an idea to collect all the pdf key word from “pdf reference” ,then add them to pdfid.ini(in your tool pdfid),then use pdfid.py to check a huge number of malicious pdf documents.The result is names from each file. Then use some clustering algorithm to filter the useful pdf key word for the further quick pdf check(as one vector).
I just wondering if it make sense to collect all the pdf key word from “pdf reference” as it’s a boring task to search
each scattered official pdf key from the whole “pdf reference”.And the number is maybe several thousands.
比心!!!
Comment by Anonymous — Sunday 11 February 2018 @ 12:17
Dear Sir,
Maybe this time it can be a useful message for you. ;)
It’s about obfuscation.
I read from one paper that “##””(two # instead one) is also an obfuscation trick. And I try it by pdfid.py. (Write one sentence “/JavaScr##69ipt” into demo.txt, then run “python pdfid.py -afn demo.txt ” to parse it).
The result will be strange :
PDF Header:
/JavaScr 1
/iipt 1(1)
Maybe is’a a small bug or something beyond my understanding…smiling.jpg
Comment by Anonymous — Sunday 11 February 2018 @ 12:37
You can use option -a to check all names. See help (-h).
Comment by Didier Stevens — Monday 12 February 2018 @ 20:52
Please provide a reference to said paper.
Comment by Didier Stevens — Monday 12 February 2018 @ 20:54
The paper name is “Detecting Malicious Javascript in PDF through Document Instrumentation”. In Page 4, 2 paragraph, “Hexadecimal Code in Keyword”. And a specific picture is given in this Page 4.
Comment by Anonymous — Tuesday 13 February 2018 @ 13:55
Yes, Sir, I’ve used -a option. I use it to check a folder of malicious pdf(about hundreds).The result will be thousands names. many of them are useless private names(not official). they will confuse the “name filter”.I just want get the official name check,then filter the result from official name check to get a set of meaningful check names.
Comment by Anonymous — Tuesday 13 February 2018 @ 14:09
That doesn’t work, try it for yourself, modify a name with ##, and you will see your PDF reader will not accept it. It must be a typo in their paper.
Comment by Didier Stevens — Tuesday 13 February 2018 @ 19:01
Thanks for your patient answer!!! Happy Spring Festival!
Comment by Anonymous — Saturday 17 February 2018 @ 1:18