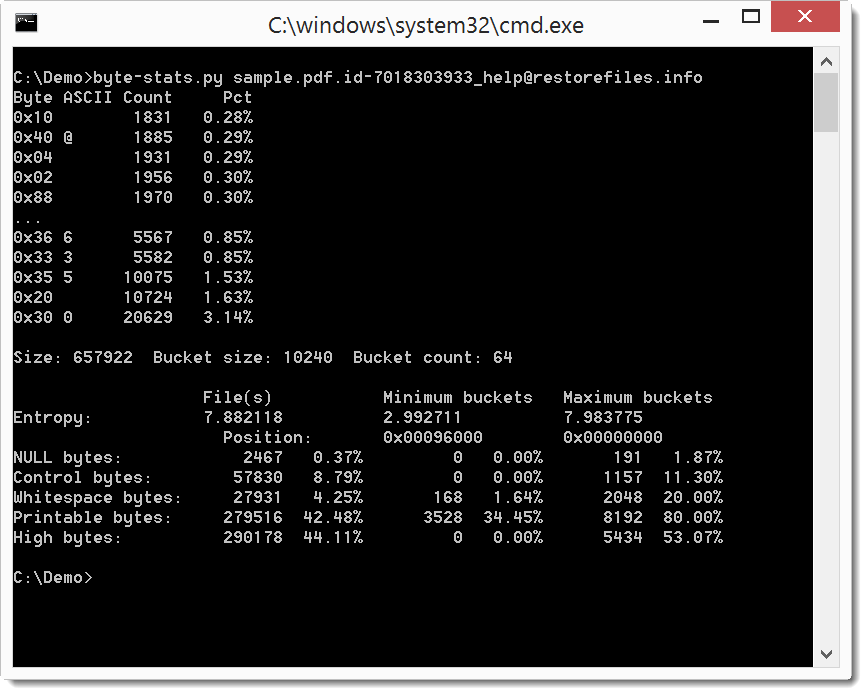
I was contacted to help with a PDF file encrypted by ransomware. Just like another case I helped with, the file was not completely encrypted. The file had parts with low entropy, as byte-stats.py shows:
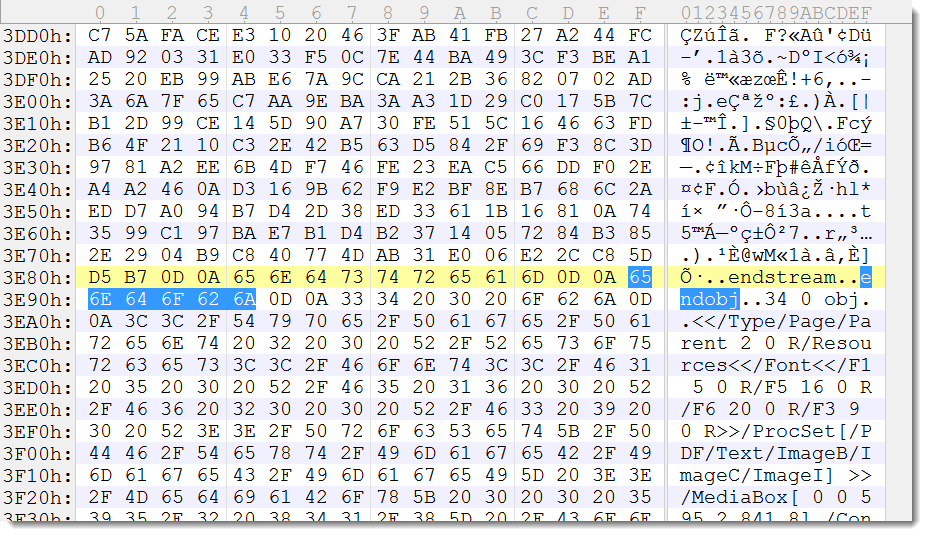
Searching for endobj, I noticed the file contained PDF objects:
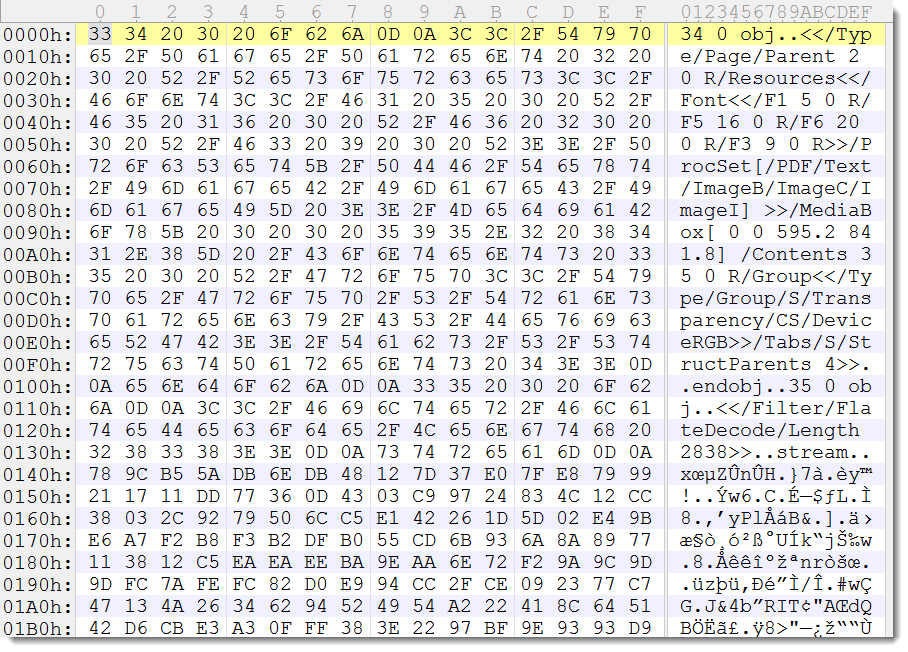
So I stripped the beginning of the file that was encrypted:
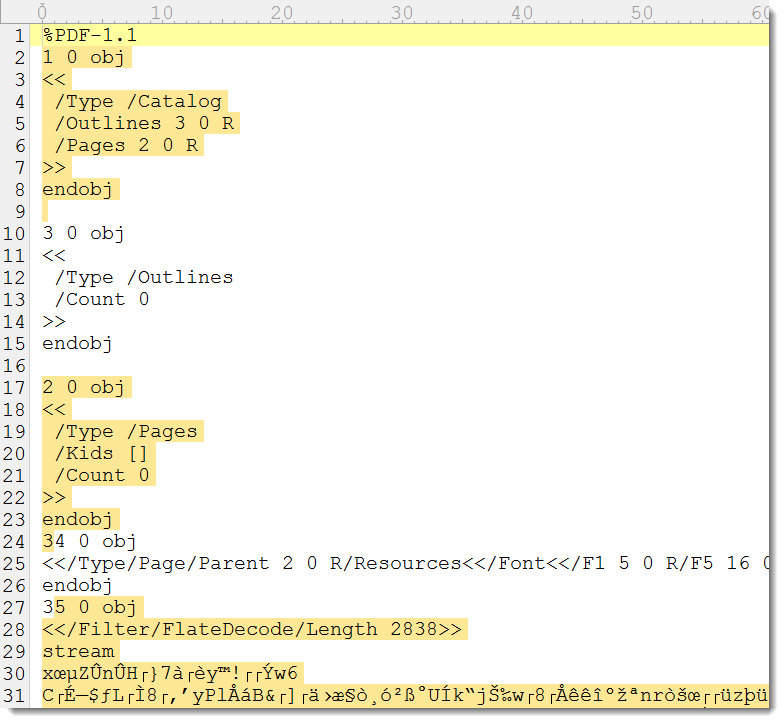
This file can be parsed by pdf-parser. Now I’m going to try to rebuild this PDF. First I check if it contains an object referencing all pages:
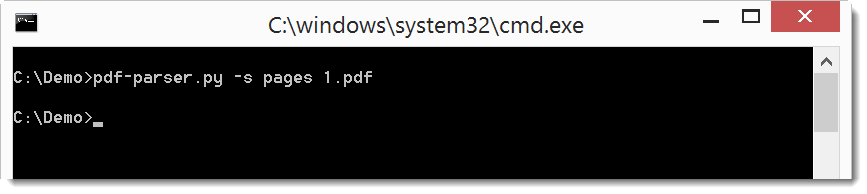
As you can see, it doesn’t. So I will add the missing objects:
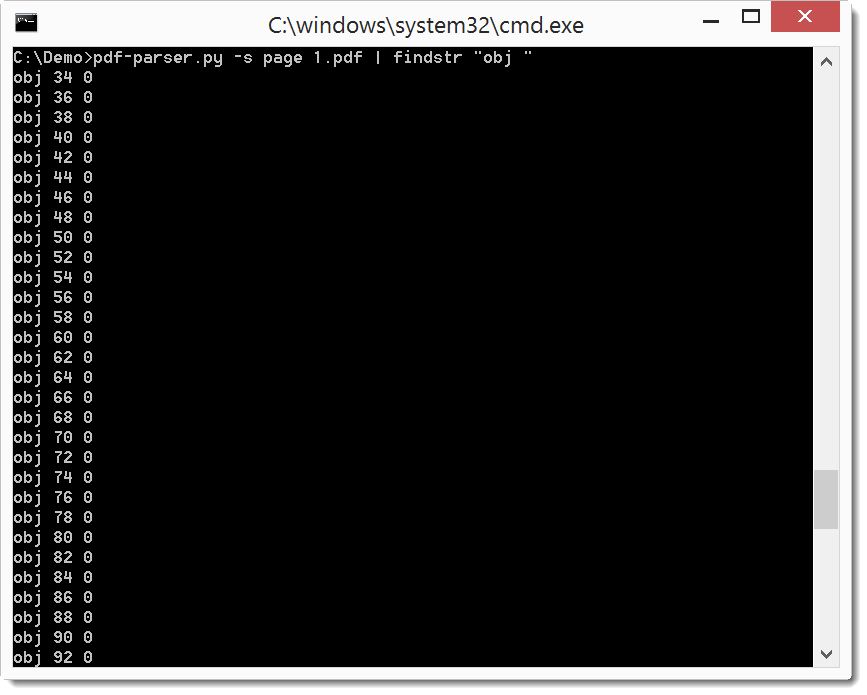
Object 2 (the missing /Pages object) needs to reference all pages still present in the document (/Kids list). I make a list of all /Page objects with the following command:
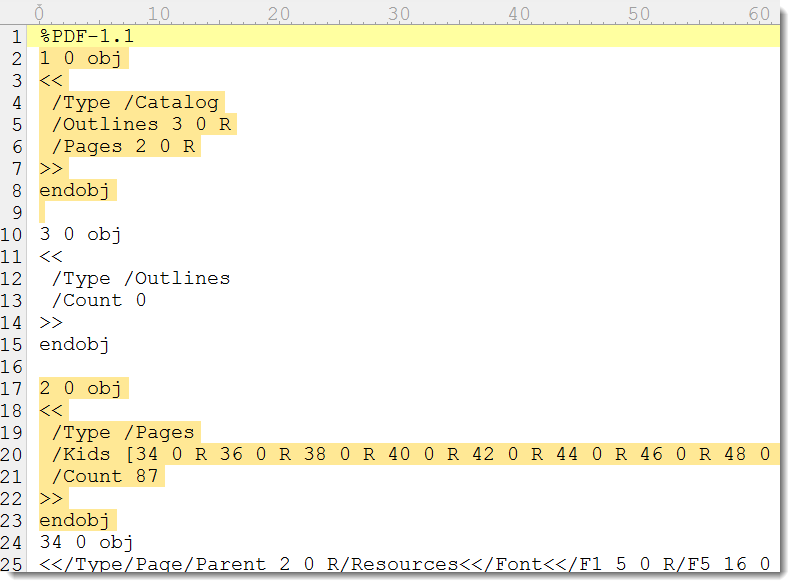
And then I update object 2 /Pages with the 87 /Page objects I found (dictionary entries /Kids and /Count):
When I open this PDF with a PDF reader, I get 87 pages. All of them are blank, except the last one:

The pages are blank because of missing fonts definitions:
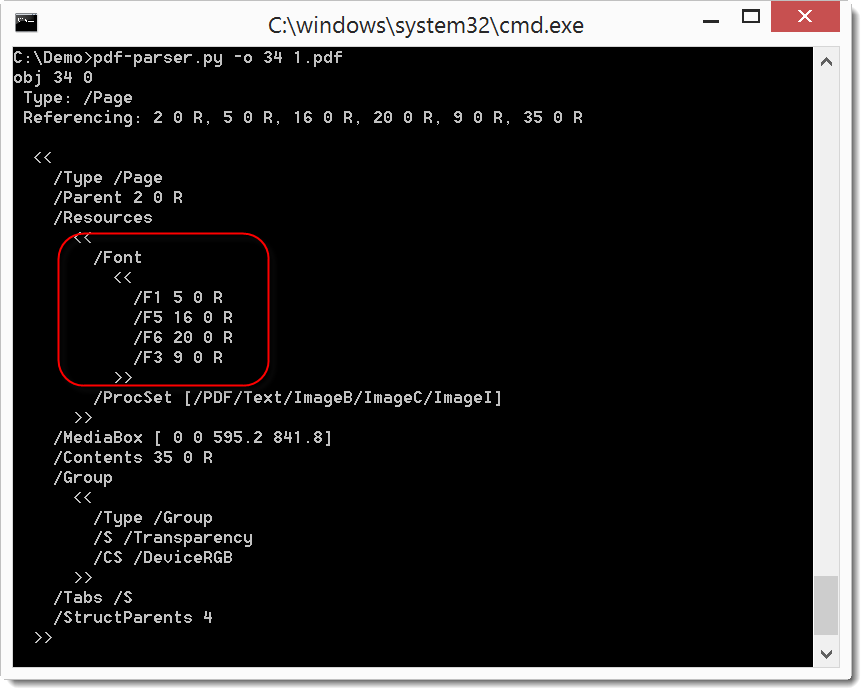
I add some generic font definitions:

This gives me the following PDF:

AS you can see, not all text is readable, that’s because I did not select the right font. Some trial and error with different fonts would allow me to further recover the document.
This method can also help you with corrupt PDF documents. Of course, this is not a complete recovery. We miss the first pages that were encrypted.

[…] Récupérer un PDF chiffré par un ransomware par Didier Stevens […]
Pingback by Newsletter Cybersécurité semaine 24 - Adacis — Saturday 11 June 2016 @ 12:02
[…] Didier Stevens presented a case study where he was given a partially encrypted PDF file and was able to recover a large majority of it by rebuilding the unencrypted sections. Recovering A Ransomed PDF […]
Pingback by Week 23 – 2016 – This Week In 4n6 — Sunday 12 June 2016 @ 14:27
[…] Recovering A Ransomed PDF […]
Pingback by Overview of Content Published In June | Didier Stevens — Sunday 17 July 2016 @ 0:00