I’m publishing my pdf-parser tool featured in my last video. Details and download here.

I’m publishing my pdf-parser tool featured in my last video. Details and download here.
A malicious PDF file I analyzed a couple of months ago (the one featured in this video) had a corrupted stream object. It uses a /FlateDecode filter, but I could not find a way to decompress it with the zlib library. Back then, I wrote it off as an error of the malware author.

Lately, I’ve been analyzing some shellcode, and while looking at the shellcode in said malicious PDF, I saw it! The second-stage shellcode, a egghunt shellcode, is searching through process memory for the 8 bytes at the beginning of the corrupted stream object.

The malware author knows that the PDF reader loads the PDF document in memory, so he just overwrote the stream object with his third-stage shellcode. This way, his third-stage shellcode is already in memory, waiting to be found by his second-stage shellcode. And the size of his third-stage shellcode is not limited by the buffer he is overflowing.
This starts a series of post leading up to my PDF talk at the next Belgian ISSA and OWASP chapter event. I’ll be publishing a couple of my PDF tools.
Next video shows how I use my PDF parser to analyze a malicious PDF file, and extract the shell code.
Searching for keyword javascript yields 2 indirect objects referencing /JavaScript objects. The JavaScript is executed through an automatic annotation (/AA) when the page is rendered (e.g. when the PDF document is opened, as it contains only one page). Decompressing the second /JavaScript object (34) displays the code.
collectEmailInfo is an undocument Adobe Acrobat JavaScript method with a vulnerability (fixed in Adobe Acrobat Reader 8.1.2). My Spidermonkey helps me to extract the shell code.
YouTube, Vimeo and hires Xvid.
Foxit Reader has been my default PDF reader for more than a year now, as an alternative to the Adobe Acrobat Reader that stalled too often when starting up.
While playing with the PDF file format, I created several PDF files that uncovered potential security issues with Foxit Reader.
A PDF file with an OpenAction triggering an URI action causes Adobe Acrobat to prompt the user for approval, before accessing the URI:

But Foxit Reader opens Internet Explorer and visits the site without confirmation prompt. I submitted a feature request to Foxit Software for this.
Another example is a JavaScript inside a PDF file that switches the reader to full screen mode. Adobe Acrobat Reader will warn you for spoofing attacks and ask for your permission to switch to full screen, while Foxit Reader does this immediately.
Of course, these warnings will only help a user that is aware of the potential risks. But in a corporate environment, you can also set the appropriate registry keys to block all these actions by default.
It was also trivial to assemble some simple malformed PDF files that cause problems for Foxit Reader, but not for Adobe Reader. I submitted these files to Foxit Software.
Adobe Acrobat Reader allows you to disable JavaScript. Until recently, Foxit Reader required a JavaScript plugin for JavaScript support. Omitting the plugin was a simple way to disable JavaScript. But since version 2.2, JavaScript is embedded in the main executable and there is no configuration switch to disable it. Many Foxit Reader users have requested this feature.
If you absolutely want to disable JavaScript in Foxit Reader 2.3, there’s a quick and dirty trick. Search for the ASCII string JavaScript (preceded and terminated by byte 00) in the Foxit Reader executable (you should find only one occurrence), and replace it with javascript, for example. Actually, this patch will not disable the JavaScript interpreter for Foxit Reader, but it will prevent Foxit Reader from recognizing the /JavaScript name in a PDF document, effectively making it to ignore JavaScript instructions (names are case-sensitive).
You can make this patch permanently by editing the Foxit Reader executable with an hex editor, or do it temporarily by patching in memory with my bpmtk utility. The command to achieve this is:
search-and-write module:. hex:004A61766153637269707400 hex:006A
Of course, this is not a serious risk analysis of Foxit Reader. I started to use Foxit Reader as a solution to the Adobe Acrobat Reader performance problems, not for security reasons. And now that I’ve delved into the PDF file format, I did some random tests with Foxit Reader and Adobe Acrobat Reader. This gave me the impression that Adobe has more experience with security risks and vulnerabilities, than Foxit Software, and that this experience is reflected in the design of their products.
I’ll still be using Foxit Reader as my main PDF reader, and I’ll still analyze suspect PDF files in a controlled environment.
I like to embed the EICAR Anti-Virus test file in usual formats and less usual formats. Today, I’m publishing a PDF document with an embedded EICAR test file (eicar.txt). This PDF document has also an annotation with a JavaScript action linked to it. Clicking the annotation will export the embedded eicar.txt file to a temporary folder and launch the default editor for .txt files. This doesn’t work with Foxit Reader, because Foxit doesn’t support the JavaScript method I’m using to export eicar.txt (exportDataObject). But you can still export the file manually if you use Foxit Reader.
eicar.pdf contains only ASCII characters, so you can use Notepad to see what I did. And I had do to something special, can you guess what? Post your comments!
A PDF stream object is a sequence of bytes. There is a virtually unlimited number of ways to represent the same byte sequence. After Names and Strings obfuscation, let’s take a look at streams.
A PDF stream object is composed of a dictionary (<< >>), the keyword stream, a sequence of bytes and the keyword endstream. All streams must be indirect objects. Here is an example:

This stream is indirect object 5 version 0. The stream dictionary must have a /Length entry, to document the length of the (encoded) byte sequence. The stream and endstream keywords are terminated with the EOL character(s). In this example, the byte sequence is a set of instructions for the PDF reader to render the string Hello World with a given font at a precise position. It’s precisely 42 bytes long.
In this example, the byte sequence is represented literally, but it’s possible (and usual) to encode the byte sequence. This is done with a stream filter. A stream filter specifies how the sequence of bytes has to be decoded. Let’s take the same example, but with an ASCII85 encoding:

The /Filter entry instructs the PDF reader how to decode the byte sequence (/ASCII85Decode). Notice the change of the length value. There are many encoding schemes (ASCII filters and decompression filters), here is a list:
This list is not so long, so why do I claim an almost limitless number of ways to encode a stream? I have 2 reasons:
Here is our example, where the stream is encoded twice, first with ASCII85 and then with plain HEX (I know, this is rather pointless, but it yields simple and readable examples):

Cascading filters also inspired me to create a couple of test PDF documents. For example, I’ve created a 2642 bytes small PDF document that contains a 1GB large stream (a ZIP bomb of sorts). Some PDF readers will choke on this document.
I’m quite pleased with the feedback I received for my Little PDF Puzzle, thanks all.
As promised, I’m posting the solution now, but first be sure you understand the basic structure of a PDF file.
The PDF file format supports Incremental Updates, this means that changes to an existing PDF document can be appended to the end of the file, leaving the original content intact. When the PDF file is rendered by a PDF reader, it will display the latest version, not the original content. Remember that the basic structure of a PDF file (one without incremental updates) consists of 4 parts:
A PDF file with one incremental update has the following structure:
Every object that has been modified can be found twice in the PDF file. The unmodified object is still present in the original content, and the edited version of the same object can be found in the updated content.
The cross reference table of the updated content indexes the updated objects, and the trailer of the updated content points to both cross reference tables.
When a PDF reader renders a PDF document, it starts from the end of the file. It reads the last trailer and follows the links to the root object and the cross reference tables to build the logical structure of the document it is about to render. When the reader encounters updated objects, it ignores the original versions of the same objects.
Let’s open our PDF Puzzle with a PDF reader:
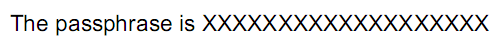
And let’s also open it with Notepad:

With Notepad, it becomes clear that I’ve created a PDF document with an incremental update (original document in red, update in blue). If you delete the updated content (the blue part, or everything after the first occurrence of %%EOF), you’ve actually recovered the original version. Save it and open it with your PDF reader:

In the original PDF document, I stored the sentence “The passphrase is Incremental Updates” in indirect object 5 (to make the puzzle a bit more challenging, I used an ASCII85 encoded stream, otherwise you could just read the solution with Notepad). Next, I updated the sentence to “The passphrase is XXXXXXXXXXXXXXXXXXX” by creating a new version of object 5 and appending this at the end of the original PDF document. To finalize the updated document, I added a new cross reference table (just indexing the new version of object 5) and a new trailer (referencing the new and the old cross reference tables).
If you produce PDF documents with a PDF editor that supports incremental updates, be aware that previous versions of your document could be included in the final document, and that this could lead to information disclosure. Most office applications that support export to PDF do not use incremental updates (because they save the document in their own native format, not PDF).
If you conduct forensic investigations or do malware research, don’t limit your analysis to the final version of a PDF document. You can easily identify incrementally updated PDF documents by looking for multiple instances of cross reference tables and trailers. But don’t get confused by Linearized PDF documents, they too have more than one cross reference table and trailer (linearized PDF documents start with an indirect object sporting a /Linearized name).
You can find interesting information in the different versions included in an incremental PDF file. For example, I have a malicious PDF sample that has been created in February 2008, updated in March 2008 to add the malicious payload (it took the author about 20 minutes) and, not surprising, that this was done on a machine with the timezone set to GMT+08.
A final detail: to allow you to edit the PDF puzzle with Notepad, I produced an ASCII-only PDF file (that’s one of the reasons I used ASCII85 encoding for the stream of indirect object 5). But most PDF documents contain non-ASCII characters, so be sure to use an editor that will support this (and that won’t convert 0x0A or 0x0D to 0x0D0A).
I have a little PDF puzzle this week. Find the passphrase in this PDF document and post a comment with your solution. There’s a very simple solution just requiring Notepad (and your favorite PDF reader).
In this post, I show how basic features of the PDF language can be used to generate polymorphic variants of (malicious) PDF documents. If you code a PDF parser, write signatures (AV, IDS, …) or analyze (malicious) PDF documents, you should to be aware of these features.
Official language specifications are interesting documents, I used to read them from front to back. I especially appreciate the inclusion of a formal language description, for example in Backus–Naur form. But nowadays, I don’t take the time to do this anymore.
While browsing through the official PDF documentation, I took particular interest in the rules to express lexemes. There are many ways to write the same token, offering opportunities to evade known-pattern recognition systems, like AV and NIDS.
Building a test file
Before I show some examples, let’s build a test PDF file that will start the default browser and navigate to a site each time the document is opened.
Opening a web page from a PDF file can be done with an URI action, like this:

This is the same type of object used in the malicious mailto PDF files.
An action must be triggered by an event, examples of such triggers are the association of an action to the display of a page or the opening of the PDF document. We will use the OpenAction to trigger our URI action object each time our test PDF document is opened:

I add the URI action object and the OpenAction event to the hello world PDF file I used in a previous post, to build our test PDF. You can download all examples here. Opening the test PDF document launches IE:

Now that we have our test PDF, let’s look at the ways we can change its representation without changing its rendering. This is what I’m covering (this list is not exhaustive):
Name representation
The tokens preceded by a / (slash) in the URI action object are called Names in the official PDF description. Names are case-sensitive. The characters used in a Name are limited to a specific set, but since PDF specification version 1.2, a lexical convention has been added to represent a character with its hexadecimal ANSI-code, like this #XX.
This allows use to rewrite the /URI name in several ways, for example: #55RI.

Or #55#52#49

Pattern matching algorithms must take into account these different representations to successfully match a pattern. A standard way to deal with this is canonicalization. First, the token is reduced to a canonical form (e.g. replace all #xx representations by the character they stand for), and second, pattern matching is performed on the canonical form.
String representation
Strings too can be represented in many forms. One way to represent strings, is to type the text between parentheses:

Splitting strings over several lines can be done by adding a backslash (\) at the end of each line:

Of course, we are not limited by the numbers of lines, we can add a backslash after each character:

A character in a string can be represented by its octal code, like this:

And this can be done for every character in the string:

One more way to represent a string, is hexadecimal:

You’re allowed to put whitespace between the hex digits:

And you’re not limited in the amount of whitespace you use:

This whitespace usage reminds me of the IE zero-byte trick in html.
I want to finish this long list of examples with PDF encryption. One more way to change the representation of a PDF document is encryption. PDFs can be encrypted without requiring the user to provide a password to view the encrypted document, this form of encryption is used for DRM. Ever had a PDF with printing or text copy disabled? That’s an encrypted PDF.
When a PDF is encrypted, only the strings and streams are encrypted, the objects themselves are not encrypted. Encrypted strings are one more way to change the representation of a string.
Here’s an example:

I know that PDF encryption has already been used to mislead SPAM filters.
Final thoughts
These many features of the PDF language providing flexibility in representation of names and strings, can also be used to generate polymorphic forms of the same malicious PDF. If you need to scan PDF documents, you need to be aware of all these features and have tools that support them.
There are indications that most AV products don’t canonicalize PDF documents prior to signature matching. I did some tests with a malicious mailto PDF document, and changing the string representation of the mailto URI action using the hexadecimal forms allows AV detection evasion. Adding whitespace wasn’t necessary, switching to hex was enough. The ClamAV source code for PDF documents has more evidence of PDF canonicalization issues in AV software, here is a string compare for the Length name without canicalization:

This will not match if hex codes are used (#).
I tested all my examples with Adobe Acrobat Reader 8.1.2 and Foxit Reader 2.2 without problems. But Foxit Reader 2.2 gave me an unpleasant surprise, more on this in a next post.
I wonder if malicious PDF samples will be used in the Race to Zero.
Here is a post to explain in detail PDF polymorphism mentioned in my BH post.
This is a simple “Hello World”-PDF viewed with a text editor:

It is composed of:
What I describe here is the physical structure of a PDF file. The header identifies that this is a PDF file (specifying the PDF file format version), the trailer points to the cross reference table (starting at byte position 642 into the file), and the cross reference table points to each object (1 to 7) in the file (byte positions 12 through 518). The objects are ordered in the file: 1, 2, 3, 4, 5, 6 and 7.
The logical structure of a PDF file is an hierarchical structure, the root object is identified in the trailer. Object 1 is the root, object 2 and 3 are children of object 1, etc…, giving this logical structure:

The physical structure of a PDF file can be transformed into another physical structure, without changing the logical structure. Here is the same file, but now the objects are ordered from 7 to 1 (I reversed the order in which the objects appear in the file):

I also had to update the cross reference table, because each object is located at a different position now. But apart from that, nothing has changed. The root is still object 1, and the tree is the same. In other words, the logical structure of the file remained unchanged, which implies that the rendering of both PDF files is identical. Objects can appear at random positions in a PDF file without impact on the logical file structure (i.e. rendering). For this simple file, with 7 objects, I have 5020 5040 (that’s 7!) possible physical structures, just by reordering the objects. And reordering objects is just one way to mutate the physical structure of a PDF file.
You can download both PDF files here.
