Some extra information when signature is found.
1768_v0_0_19.zip (http)MD5: FCF07B2AEDDBB4911520152531C5F107
SHA256: 5EE73B9311578D202246011FAF3216674387894833E759148F6C5356B646686F
Some extra information when signature is found.
1768_v0_0_19.zip (http)This update adds ZIP support for binary files, and a –prompt option.
When this option is used, the user is prompted after each request, and processing of new requests is suspended until the user reacts to the prompt.
simple_listener_v0_1_4.zip (http)This update adds option –group: with this option, all lines are stored as a list in variable lines, and the Python expression is evaluated just once after each file is processed.
python-per-line_V0_0_11.zip (http)This new version adds YARA support.
myjson-filter_V0_0_5.zip (http)This new version adds two new values for option -l.
One could already use option -l P to locate all PE files inside an arbitrary binary file.
Option -l PE also adds entries for the extra (E) data, e.g., the data in between found PE files.
Option -l PO is like PE, but adds some more information for the other (O) files: the magic header (hex & ASCII).
pecheck-v0_7_16.zip (http)This is just a small update to my XOR known-plaintext attack tool, with some improvements on the algorithm.
xor-kpa_V0_0_8.zip (http)This updates changes the THP_READALL logic, and adds THP_ECHO_THIS and THP_ALLOW_LIST.
simple_listener_v0_1_3.zip (http)This new versions adds 2 new features:
Option -H adds a human hash for each hash:

Option -r renames a file to its hash (hash) or to its hash with extension .vir (vir).
When more that one hash algorithm is used (default: md5, sha1, sha256), the last hash algorithm is used for the rename operation.

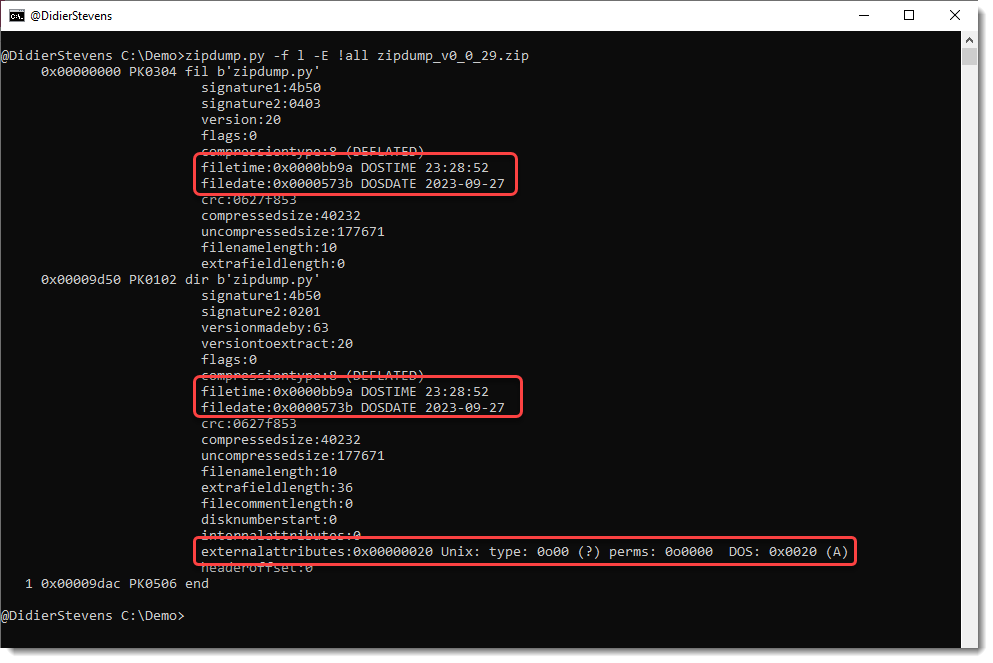
This update of zipdump.py adds parsing for external attributes and DOSDATE and DOSTIME fields when options -f and -E are used.
This update is just a definition update to detect MSO (ActiveMime files).
file-magic_V0_0_7.zip (http)