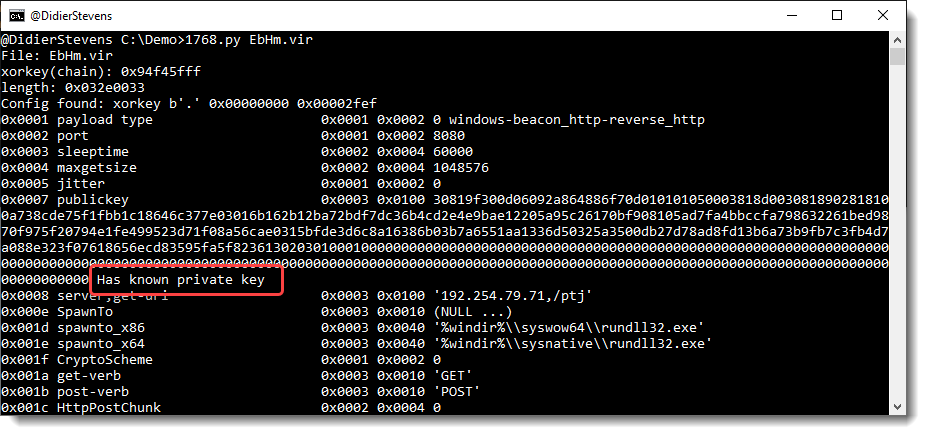
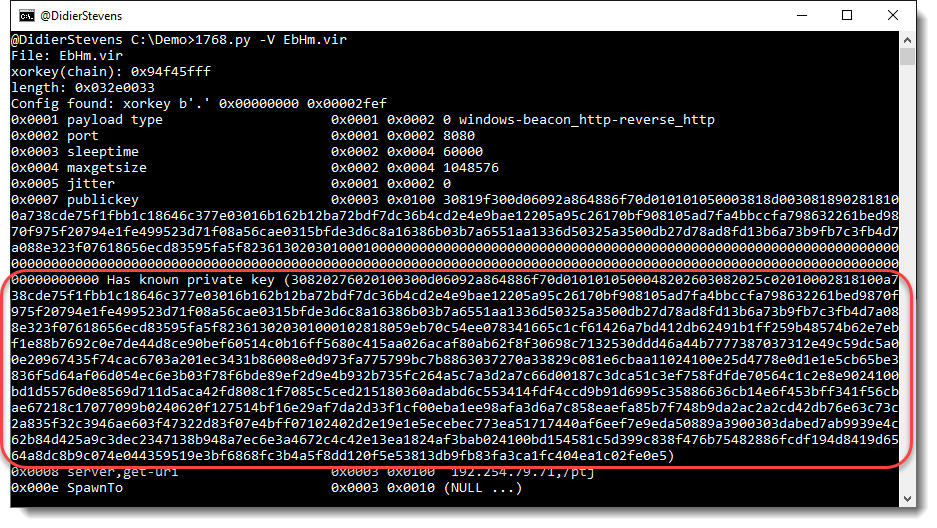
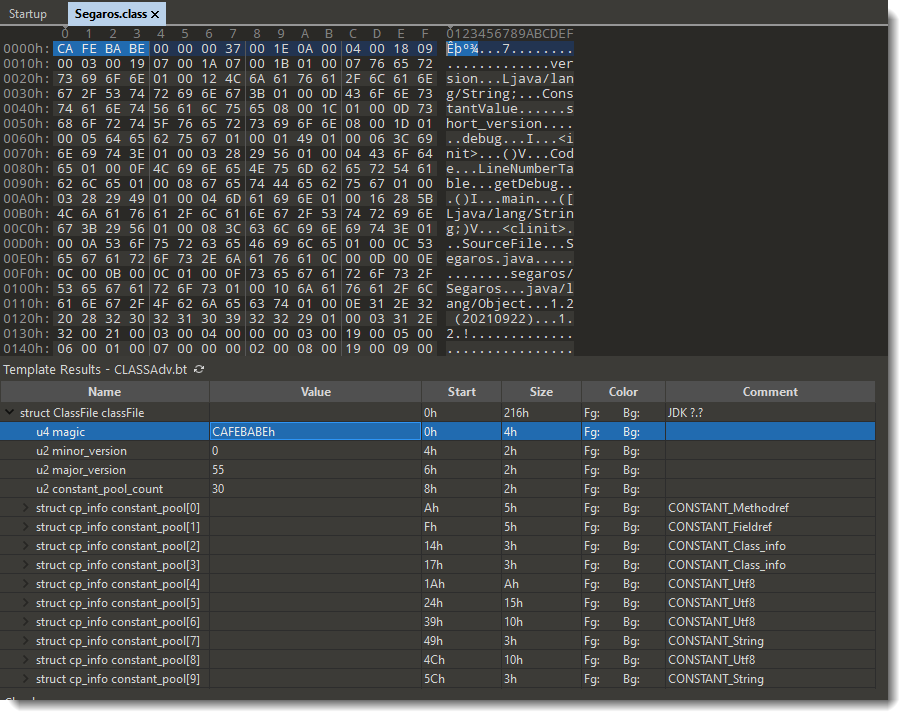
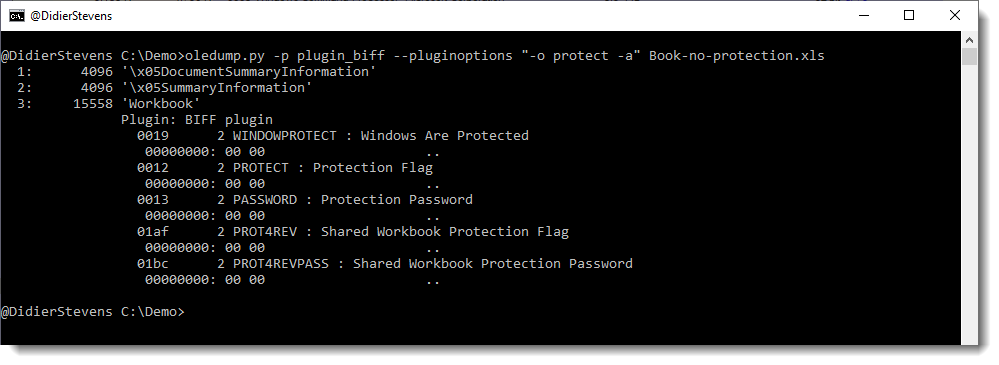
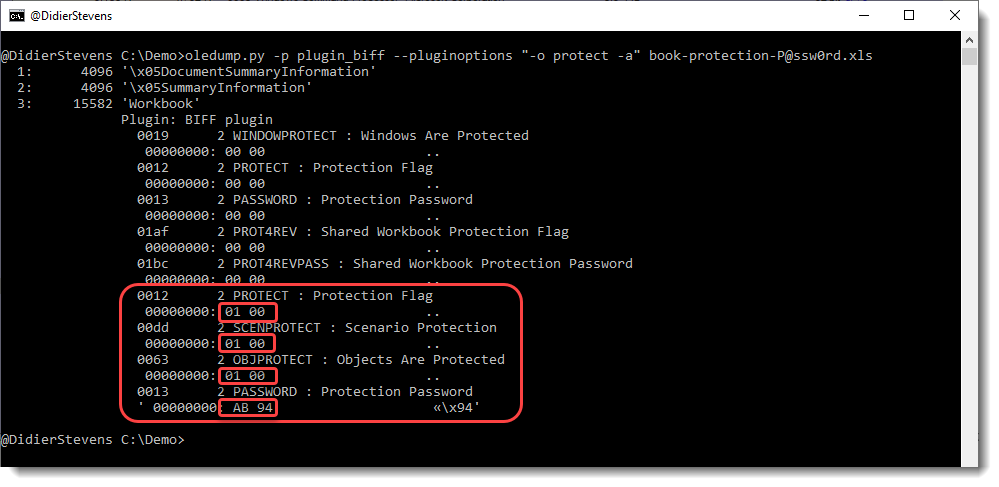
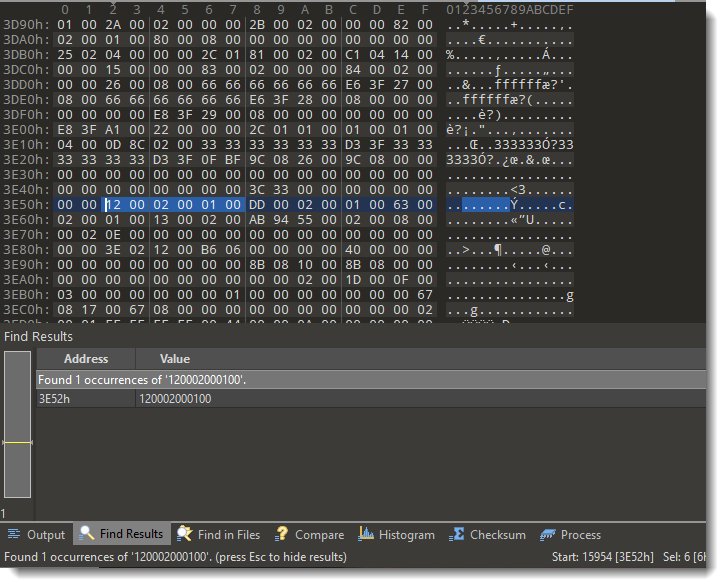
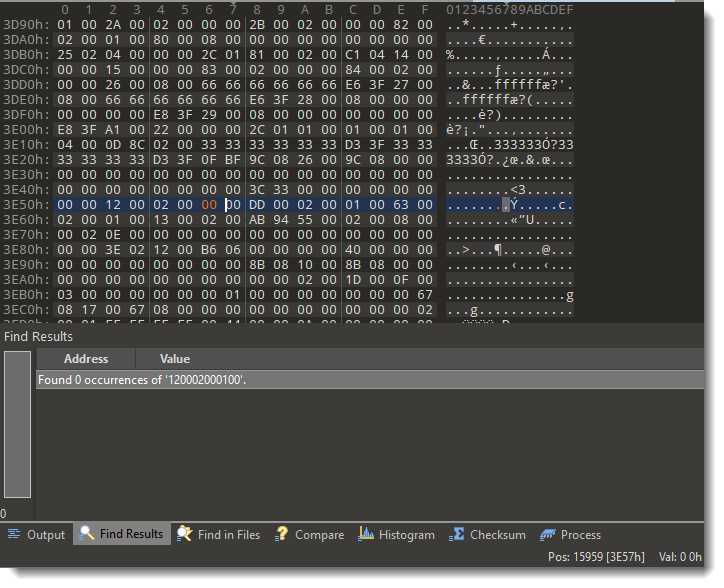
We have seen ISO files being used to deliver malicious documents via email. There are different variants of this attack.
One of the reasons to do this, is to evade “mark-of-web propagation”.
When a file (attached to an email, or downloaded from the Internet) is saved to disk on a Windows system, Microsoft applications will mark this file as coming from the Internet. This is done with a ZoneIdentifier Alternate Data Stream (like a “mark-of-web”).
When a Microsoft Office application, like Word, opens a document with a ZoneIdentifier ADS, the document is opened in Protected View (e.g., sandboxed).
But when an Office document is stored inside an ISO file, and that ISO has a ZoneIdentifier ADS, then Word will not open the document in Protected View. That is something I observed 5 years ago.
But this has changed recently. When exactly, I don’t know (update: August 2021).
But when I open an Office document stored inside an ISO file marked with a ZoneIdentifier ADS, Office 2021 will open the document in protected view:

With an unpatched version of Office 2019, that I installed a year ago, that same file is not opened in Protected View:

After updating Office:

Word’s behavior has changed:

The file is now opened in Protected View.
If you want to test this yourself, you can use my ZoneIdentifier tool to easily settings a “mark-of-web” without having to download your test file from the Internet:

Or you can just add the ZoneIdentifier ADS with notepad.
I did the same test with Office 2016, I updated an old version and: the document is not opened in Protected View.
I don’t know exactly when Microsoft Office 2019 was updated so that it would open documents in Protected View when they are inside an ISO file marked as originating from the Internet. But if you do know, please post a comment.
Update: this change happened in August 2021. See comments below. Thanks Philippe.