I received an Innovation Coin for the research I conduct at NVISO.

An important element in research, that doesn’t get much (public) attention, is failure.
When you perform research, know that many of the things you will try, will fail: they will not lead to the desired outcome. This is inherent to research.
Publishing failed research is useful, if only to avoid others taking the same, dead-end path. And maybe to inspire future researchers to find other paths.
I would like to show an example of some simple research I did recently, that didn’t produce the desired outcome.
While adding a new feature to my zipdump.py tool, I got the idea to bypass anti-virus detection of a payload by putting it inside the comment of a ZIP archive.
The last record in a ZIP file, is the end-of-central-directory (EOCD) record. In normal situations, this record marks the end of the ZIP file: there is no data beyond this record. One of the last fields in this record, is the comment-length field. If there is no comment (most ZIP files have no comment), the comment-length field is zero and it it the last field in the record. So it marks the end of the ZIP file.
If there is a comment, the comment-length contains the length (in bytes) of the comment, and the comment itself is the last field in the record (right after the comment-length field).
Here is a binary view of the EOCD record of a ZIP file without comment. The comment-length field (2 bytes, little-endian) is equal to zero:

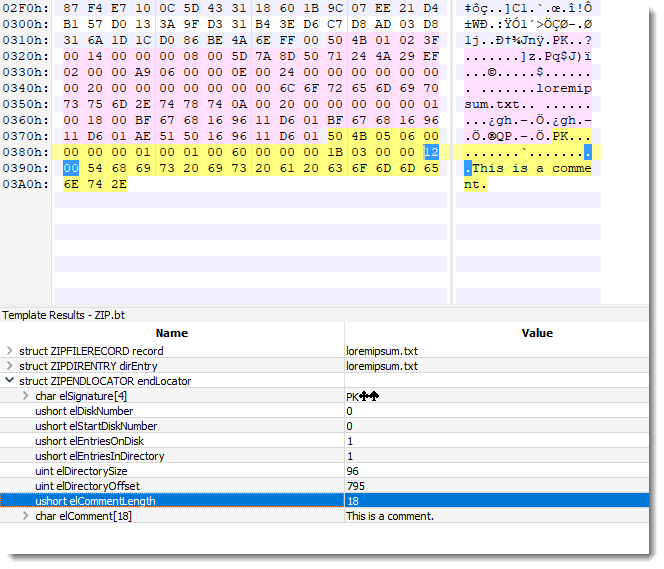
And here is an EOCD record with a comment: 18 bytes long (0x12). The comment-length field (2 bytes, little-endian) is equal to 0x12, and the comment itself is right after this field:
I created a ZIP file with the mimikatz driver as comment. Since the comment-length field is 2 bytes long, a comment can not be longer than 65536 bytes (0xFFFF). Hence I couldn’t use mimikatz.exe (it’s larger than 64KB) and had to use mimikatz.sys (33KB).
The version of mimikatz.drv I used has 55/70 detections on VirusTotal at time of writing, and stored inside a ZIP file, it has 43/62 detections.
A ZIP file containing a simple text file has 0 detections.
And the same ZIP file with mimikatz.sys as a comment, has 13/60 detections.
Here is a binary view of that file:

From these results, I could conclude that this is indeed a valid method to bypass static detection by several anti-virus products, and that my research yielded a useful bypass method.
However, I also created a file where mimikatz.sys is just appended to that ZIP file containing a text file. Not as a comment, just appending one file to another. And here the detection rate on VT is just 4/61.
This is a simpler and better method, one that is already known and used by many actors on the Internet.
Remark that I used VirusTotal here for quick results, but that the anti-virus products on VirusTotal are limited in their detection capability, compared to the same AVs deployed on endpoints.














